Hello,
We have been testing Zammad with 3 employees for several months.
In the future, around 60-70 employees will work with it - around 30-40 of them at the same time.
Infos:
Used Zammad version: 5.2.3
Used Zammad installation type: Package
Operating system: Ubuntu 20.04
Browser + version: Different (Chrome, Firefox, Edge)
Expected behavior:
Staff actions like ticket creation should be done within 5 seconds.
Actual behavior:
During setup and testing, we primarily tested with 1-3 people and everything worked as expected - the performance was okay (ticket creation took about 2-4 seconds).
Yesterday we made a performance test (ticket creation and ticket updating at the same time) with 30 employees, unfortunately there were extreme delays (waiting time for e.g. ticket creation: 30-90 seconds).
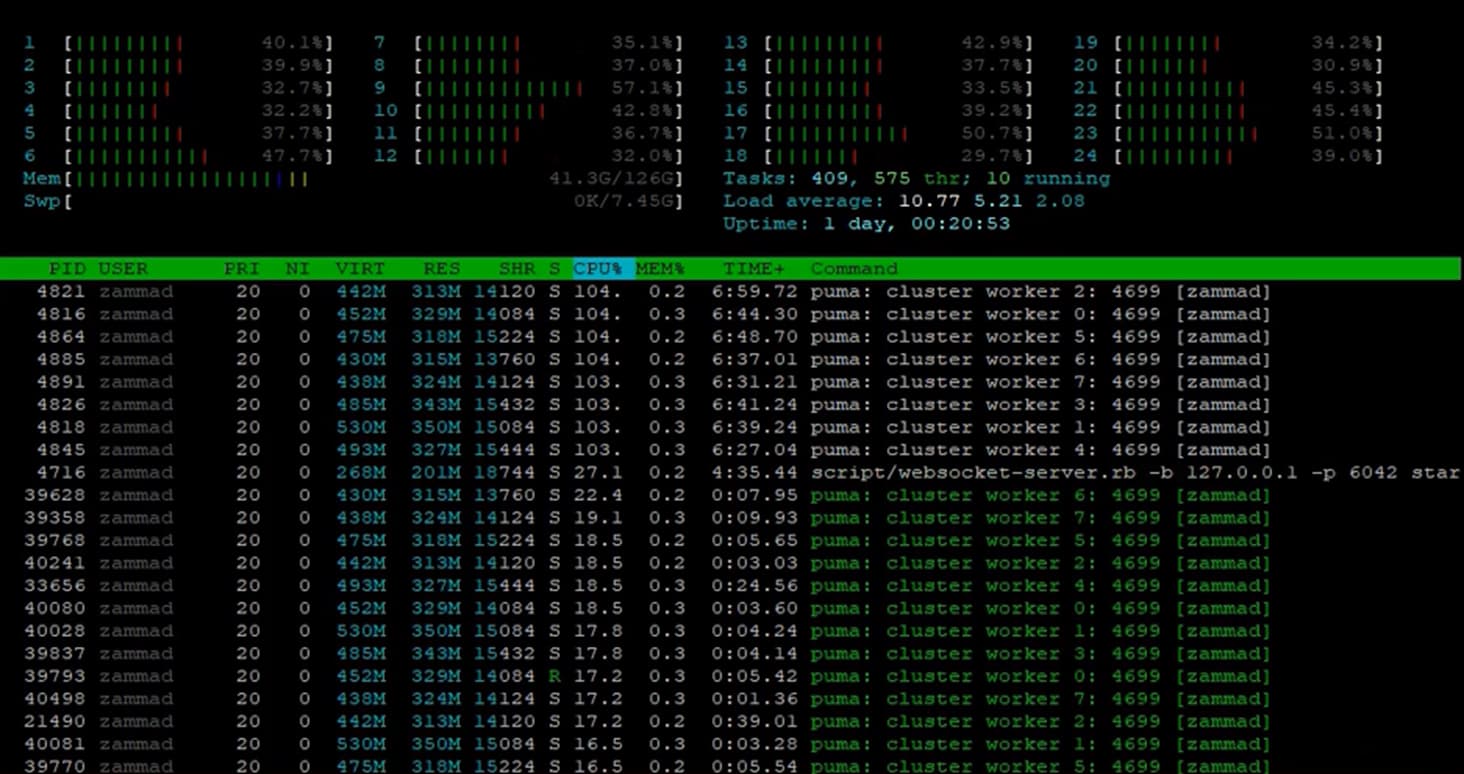
The server was not busy at the time of the test, CPU about 50% - RAM usage about 41 GB. See screenshot:
If you’re hitting the PostgreSQL max_connections limit, you should see this in your PostgreSQL logs, e.g. something like:
FATAL: remaining connection slots are reserved for non-replication superuser connections
So inspect your database logs for errors like this. Blindly raising max_connections to an arbitrary high number is a bit of a dumb idea. Here is a pretty good write-up on the subject.
I would start looking for I/O bottlenecks, e.g. disk or database. The data you’ve supplied doesn’t mention this and your platform’s resources seem like quite a bit of overkill, the problem isn’t likely to be in the number of CPU cores or the memory, when looking at the data, although you might need to convince the middleware (Apache/NginX, PostgreSQL, ElasticSearch) to actually utilize it, by tuning it a bit more to the massive specs. Another issue could be deadlocks in the database, due to the high number of concurrent users all wanting to write to the database tables. Configure PostgreSQL to actually start logging information about locking issues (log_lock_waits = on) and Inspect your database logs.
Regarding PostgreSQL tuning: we have set maintenance_work_mem and autovacuum_work_mem to higher values. We have turned off synchronous_commit and you should consider configuring effective_cache_size. Here’s a bit of a write-up on that subject.
Take care when setting work_mem to such a massively high value, as this setting is per individual query operation. This is fine when you’re hosting an application where only a few queries run at specific moments, which could yield huge result-sets, e.g. data-warehouse analytics queries. If the queries for basic/common Zammad functionality or daily operations need these amounts of memory, you will likely a) run into out-of-memory situations very fast and b) you’ll also need to figure out what is wrong with your data, result-sets and/or queries, as this really shouldn’t be happening.
Your effective_cache_size setting seems wrong, as this should at least include the amount of memory dedicated via shared_buffersplus the expected/estimated operating system caches/buffers available for PostgreSQL. Based on your specs, you could probably safely set this to about 64GB instead of 24GB. Please see here for more information on tuning parameters such as these. Keep in mind that if you’re running PostgreSQL on the same server as the rest of the Zammad stack, you should be conservative here.
Also, keep checking your PostgreSQL logs for anomalies during day-to-day operations when applying tuning like this, I can’t stress this enough. The tuning I did was based on daily plan-do-check-adjust cycles based on I/O statistics, realtime monitoring/logging as well as user feedback/experience.