Hi, I’m seeing that message in settings -> System -> Monitoring
16479 failing background jobs.
Failed to run background job #1 'BackgroundJobSearchIndex' 10 time(s) with 130 attempt(s).
As far as I can tell search is working. I tried manually running reindex
rake searchindex:rebuild
and it completes ok without error, but the warning count grows.
I didn’t do anything special to upgrade the installation, I just pulled the new images and downed the old ones, and upped the new ones.
I also has an LDAP sync that wouldn’t finish, but found the way to mark it finished and restart it and it synced OK. But, and I don’t know if this is related, when I drag a ticket to the bottom to assign it to someone there’s some weirdness and it doesn’t work as expected. Should I open a separate topic for that do you reckon?
I had something similar today. My problem was the there was a wrong data type stored in user preferences.
Can you execute the following via “zammad run rails c” and can you tell if you still have failing jobs?
items = SearchIndexBackend.search('preferences.notification_sound.enabled:*', 3000, 'User')
items.each {|item|
next if !item[:id]
user = User.find_by(id: item[:id])
next if !user
next if !user.preferences
next if !user.preferences[:notification_sound]
next if !user.preferences[:notification_sound][:enabled]
if user.preferences[:notification_sound][:enabled] == 'true'
user.preferences[:notification_sound][:enabled] = true
user.save!
next
end
next if user.preferences[:notification_sound][:enabled] != 'false'
user.preferences[:notification_sound][:enabled] = false
user.save!
next
}
Delayed::Job.all.each {|job|
Delayed::Worker.new.run(job)
}
I’m running it, there are over 15,000 failed jobs that I guess are being run
I’ll get back to you, i imagine it will be tomorrow for me, in about 16 hours.
Wunderful. There is already an issue https://github.com/zammad/zammad/issues/1933 - I’ll create an migration for that to cleanup all instances (in case there is the same issue).
@martini got the same issue, this statement didn’t fix the problem for me.
Currently: Failed to run background job #1 ‘BackgroundJobSearchIndex’ 4 time(s) with 22 attempt(s).
So now my monitoring has the following state: 11 failing background jobs. Failed to run background job #1 'BackgroundJobSearchIndex' 10 time(s) with 236 attempt(s).
@MrGeneration, I had the Failling backgroub jobs error again. This time the cause was different. I had an article with an xlsx attachment (I think it was 4M) and the POST request to add it to the index was timing out. I think the timeout 12 seconds by default. I tried bumping it up to 60 and it still timed out. So I added xlsx to the ignore list by running in the “rails c”
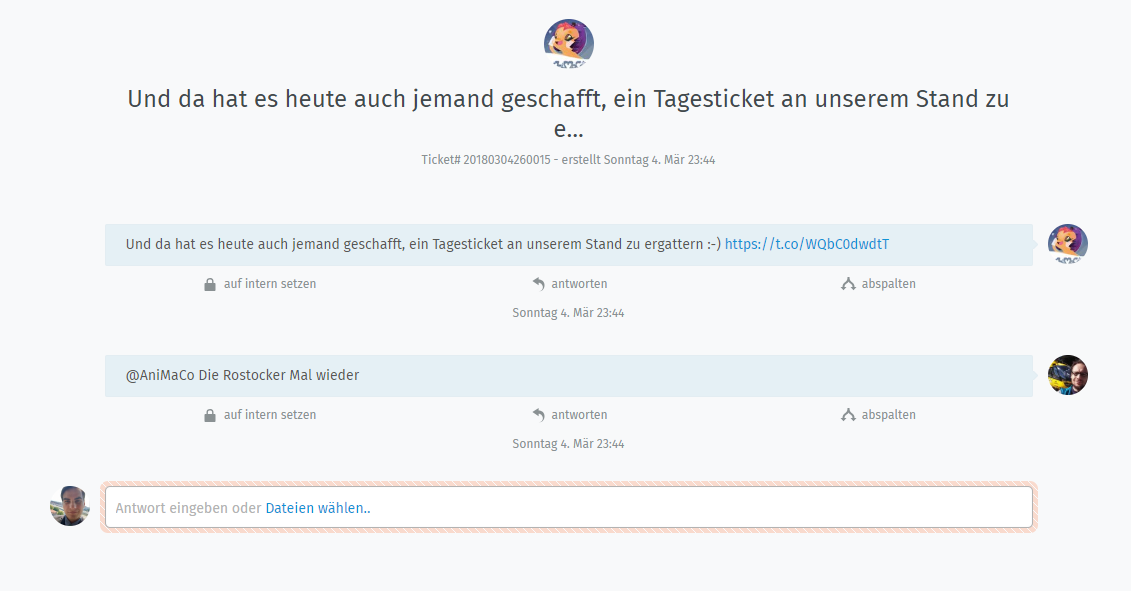
Your error looks similar in that it’s a ticket that’s causing the problem, but it’s not the same problem. I don’t know what it is but it doesn’t like something about ticket 890.
@chesty thanks for your input. I’ve taken a look into Ticket #890 because I was interested, what makes this ticket so special. My problem: I have no idea, this Ticket has no attachment and actually comes from channel “Twitter”
I’m having the same issue after running a large LDAP sync over the weekend that failed.
Failed to run background job #1 ‘BackgroundJobSearchIndex’ 5 time(s) with 5 attempt(s).
Right now it has broken notifications, both email and on the Zammad dashboard.
I’m running what @martini recommended but it’s going to take some time to finish with the size of our environment. What’s interesting is that a few seconds after running his command it pushes notifications through but not permanently as notifications are not working right now.
I thought the notification_sound bug had been fixed, I just looked in github, I think it was in late april for 2.4.1
Maybe you need to update to the latest 2.4?
Also 2.5 was released a few days ago.