The Zammad system is not stable since 6 days and we would like to fix that ASAP.
Our zammad log file showing some errors, the most common:
Unable to process GET request to elasticsearch URL 'http://127.0.0.1:9200/zammad_production/User/_search'.
Couldn't find Ticket with 'id'=XXXX (ActiveRecord::RecordNotFound)
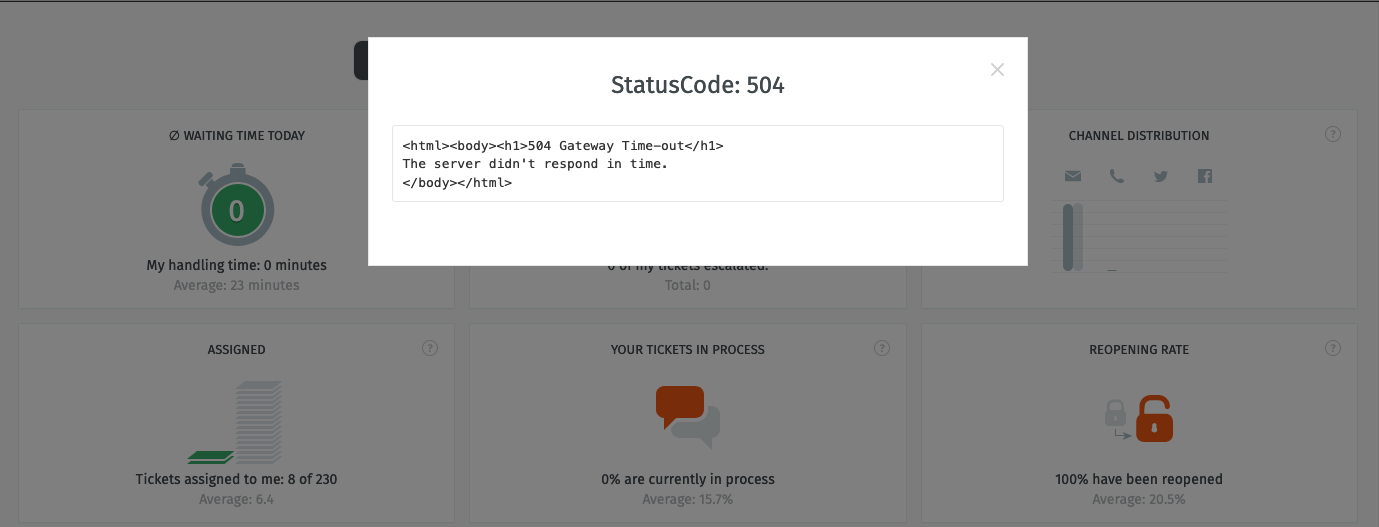
We also having a gateway time-out message in the browser for like every 10 minutes:
Several things:
Your Notification-Channel seems to be misconfigured or your server: E, [2019-12-19T05:52:34.388815 #18127-47132450386340] ERROR -- : Connection refused - connect(2) for "x.x.x.x" port 25 (Errno::ECONNREFUSED)
Also, you have dozens of these errors which is not normal behaviour.
(aka what are you doing? Can be a automatic API script doing stuff or your agents keep on trying to create users that with a already known mail address, looks strange to me):
E, [2019-12-19T08:42:30.468530 #18127-70322478911140] ERROR -- : Email address is already used for other user. (Exceptions::UnprocessableEntity)
Then tons of parsing issues (potential issue with file system):
E, [2019-12-19T12:19:20.926102 #18127-47132462069260] ERROR -- : #<JSON::ParserError: 785: unexpected token at ''>
E, [2019-12-19T12:19:20.945466 #18127-47132462069260] ERROR -- : error in reading/parsing session file '/opt/zammad/tmp/websocket_production/1234/session', remove session.
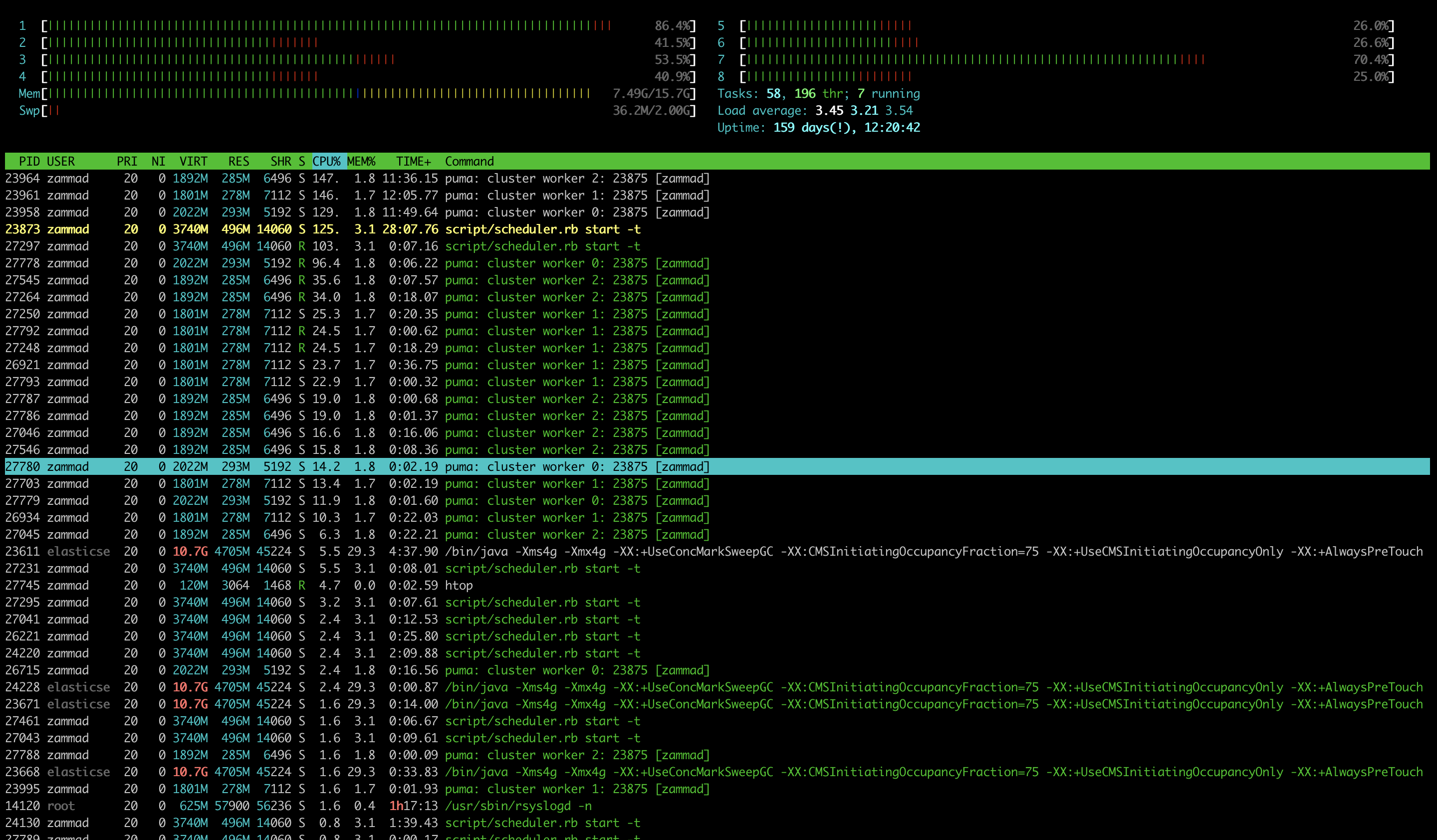
Beside of that, your load doesn’t match to an 8 core machine, looks low (which is perfectly fine!).
Might be a sign of too few PUMA-Processes which normally are spawned automatically, you can however turn the number up manually. you can try going to 4 - 8 (monitor your system just in case if you do). You can find more information on puma “WEB_CONCURRENCY” here:
Also, during runtime where this issue occurs, could you please run the following commands and provide their output here?
zammad run rails r "p User.joins(roles: :permissions).where(roles: { active: true }, permissions: { name: 'ticket.agent', active: true }).uniq.count"
zammad run rails r "p Sessions.list.count"
zammad run rails r "p User.count"
zammad run rails r "p Overview.count"
zammad run rails r "p Group.count"
The average load of your system during the appearance of these issues would be helpful too.
Beside the above mentioned log messages, your log looks just fine.
What I noticed is that your response times is climbing from 500ms to up to 7000ms (worst was about 27000ms, that’s no good) which can have various reasons. Most likely one of the following things:
the I/O of your system is too slow which causes high waiting times (this causes delay that blocks Zammad in delivering content, that causes 500 errors)
your database is not fast enough
your ESXi is using fair queing and is under high load which can cause your mentioned issues
you overbooked ressources - try to ensure that provided ressources are exclusive for Zammad
Your agents are opening big tickets (with 50 articles and more, “big” depends a bit on the content, but this will also be noticable on the UI when the browser starts lagging for example)
@MrGeneration
Sorry for the big delay…
We unfortunately still having the same above issues and also from this morning we are not receiving email notifications about the created tickets, for that i would like to open this topic again.
First i’ll provide you with the commands output you asked before:
zammad run rails r “p User.joins(roles: :permissions).where(roles: { active: true }, permissions: { name: ‘ticket.agent’, active: true }).uniq.count”
38
zammad run rails r “p Sessions.list.count”
21
zammad run rails r “p User.count”
5830
zammad run rails r “p Overview.count”
19
zammad run rails r “p Group.count”
15
Maybe some more helpul informations:
max_connections = 100
“WEB_CONCURRENCY” = 3
database.yml = pool set to 100
What is strange for me is i can see several puma and elastic commands running in the at the same time/eating too much memory:
You’re allowing to take Zammads pooling up to 100 database connections per process.
Usuually you want to multiply pool: 50 by 4 processes which makes 200 already.
Your postgresql-Server only allows 100 connections at the same time - as Zammad keeps connections opened, this is your bottle neck and the reason you have an arrow in the knee.
Raise max_connections to 1000 to 2000 which should be fairly enough.
Don’t forget to restart postgresql and Zammad by
Several puma processes are perfectly fine and needed. That’s no issue at all.
For the memory thing: You might want to upgrade to Zammad 3.2 which saves up to 38% of memory usuage over long time. Up to 3.1 the garbarage collection is a bit off which causes especially the scheduler to get a fat heavy boy.
Another heads up on your overview-count.
It looks fairly high with 19 overviews.
I am sure you have your seasons, but your scheduler is already running at 100% (so your cores maximum) which might lead to performance issues in general.
Causes are most likely overviews, many updates in combination with many delayed jobs (searchindex updates and mail communication).
As soon as you have the feeling that your overviews take way to long (60-300 seconds or worse) to update the ticket list, you’re having performance issues.
Try to reduce overviews. Most of the times one overview can provide enough information for 2 or 3 (if you chose to have group dependend overviews for example). Also ensure you have not too many tickets inside your overviews, everything above 2100 doesn’t make any sense any way, but keeping it below 1000 should be a good idea.
I hope this helps you further.
Edit on the Overview and Session combination I complain about:
If you have 19 overviews and 21 active agents, Zammad will calculate 19 overviews per agent.
In total your scheduler will thus need to calculate 399 overview views for all of your active agents.
You can imagine how much stress this means for your CPU. That’s why I suggest reducing them -if possible-
Zammad 3.2 comes with enhancements on performance and overviews, so it might help as well.
You want to set max_connections: 2000 in your postgresql configuration, correct.
Increasing the database.yml pool would worsen your issues at this moment. 100 is already fairly high and shouldn’t be required with your current requirenments.