Used Zammad installation type: (source, package, docker-compose, …) Package
Operating system: Ubuntu 20
Browser + version: All
Expected behavior:
Our system, although far from being heavily utilized, is extremely slow. When we started on a fresh install performance was fantastic, and a ticket would load immediately.
Now any ticket would take 3 to 10 sec to load, and even logging in takes time after login / pwd are entered.
Even when connecting for an SSH session the prompt would take 10 to 15 second.
The system is obviously overload, but why is the question… we suspect Elasticsearch…
We are running a VM with 16Gb of RAM and 16 Core, on a iSCSI drive over a 10gb/s dedicated link. Our system has 5 to 10 simultaneous users (agents+customers).
That seems like a beefy VM, but does it actually get all the CPU cycles from the host OS, or is it capped? It might also be slow due to CPU over-commitment on the hypervisor or combined with a very busy virtualization platform.
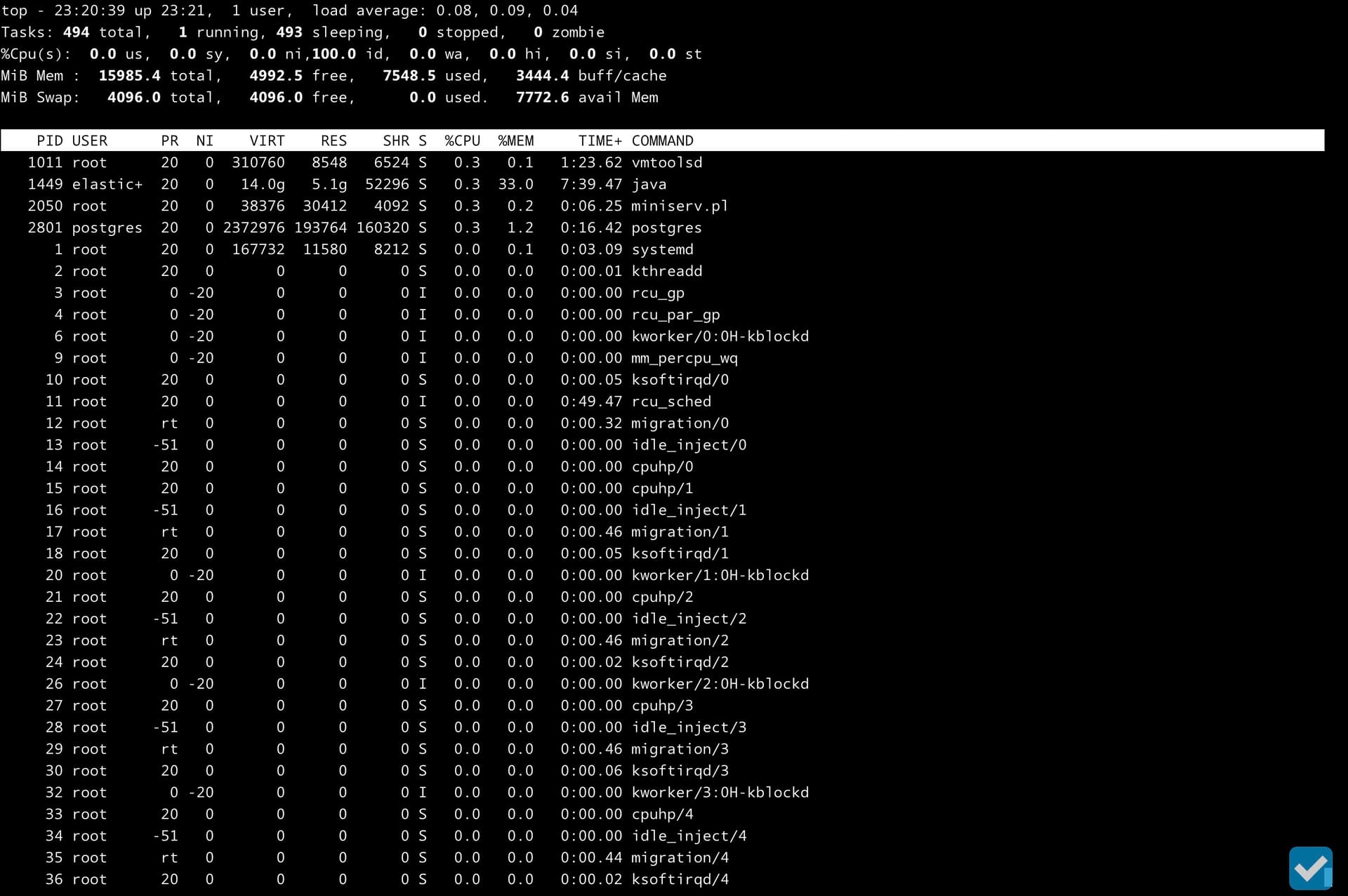
Another reason for feeling sluggish could be due to high I/O wait (slow storage), which isn’t visible on your screenshot. Maybe post the results of top or check the output of iotop for possible storage latency/bandwidth issues?
Thanks for taking the time to share your thoughts.
No the VM isn’t capped - on the contrary the physical machine has lots of unused CPU/RAM and it not limiting VMs.
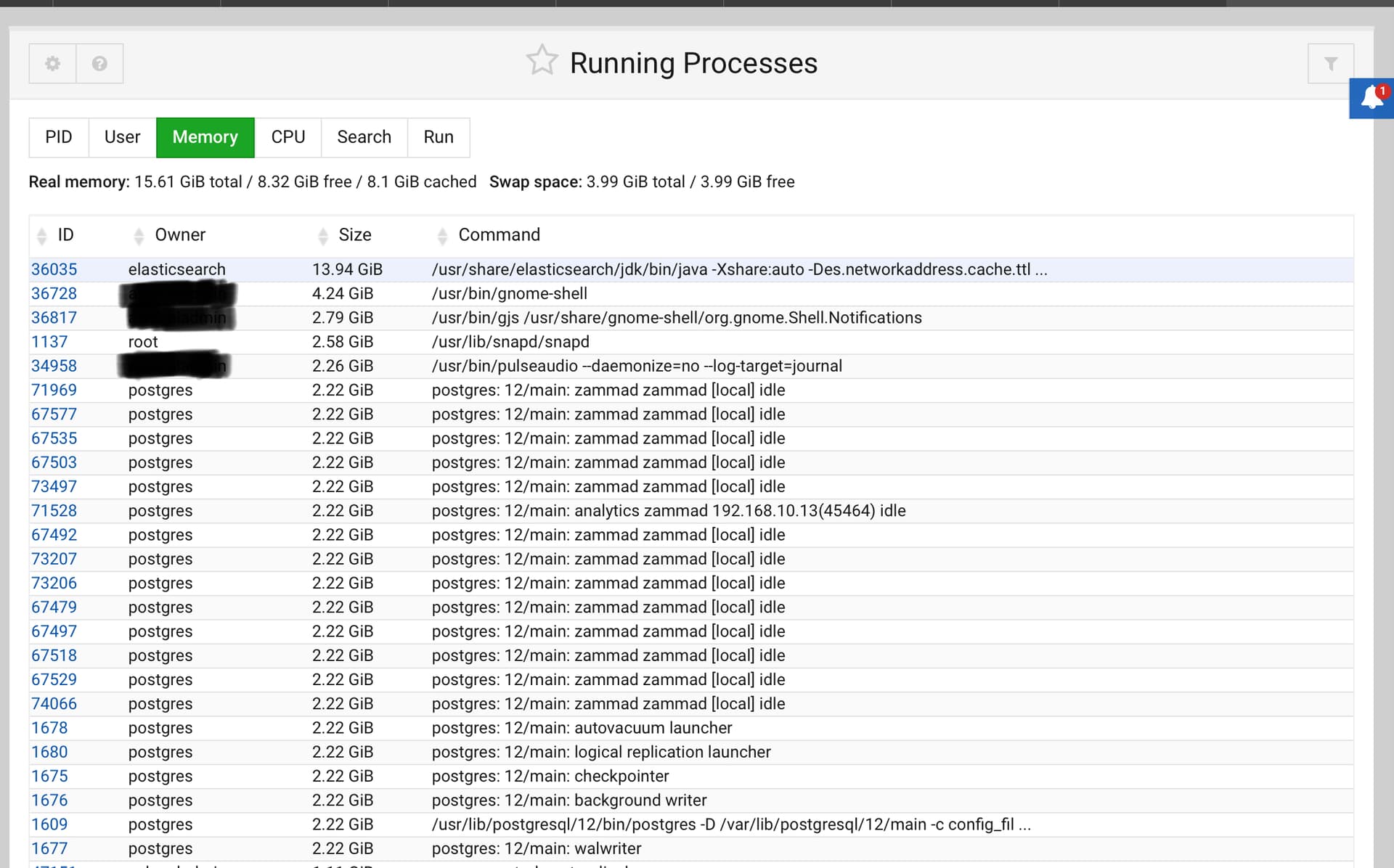
Can you see like me that Elasticsearch and postgre are kind of taking too much room on the memory?
I was also thinking about perhaps the system buffering more than needed (rely too much on the HDD buffer file as opposed to using actual RAM)
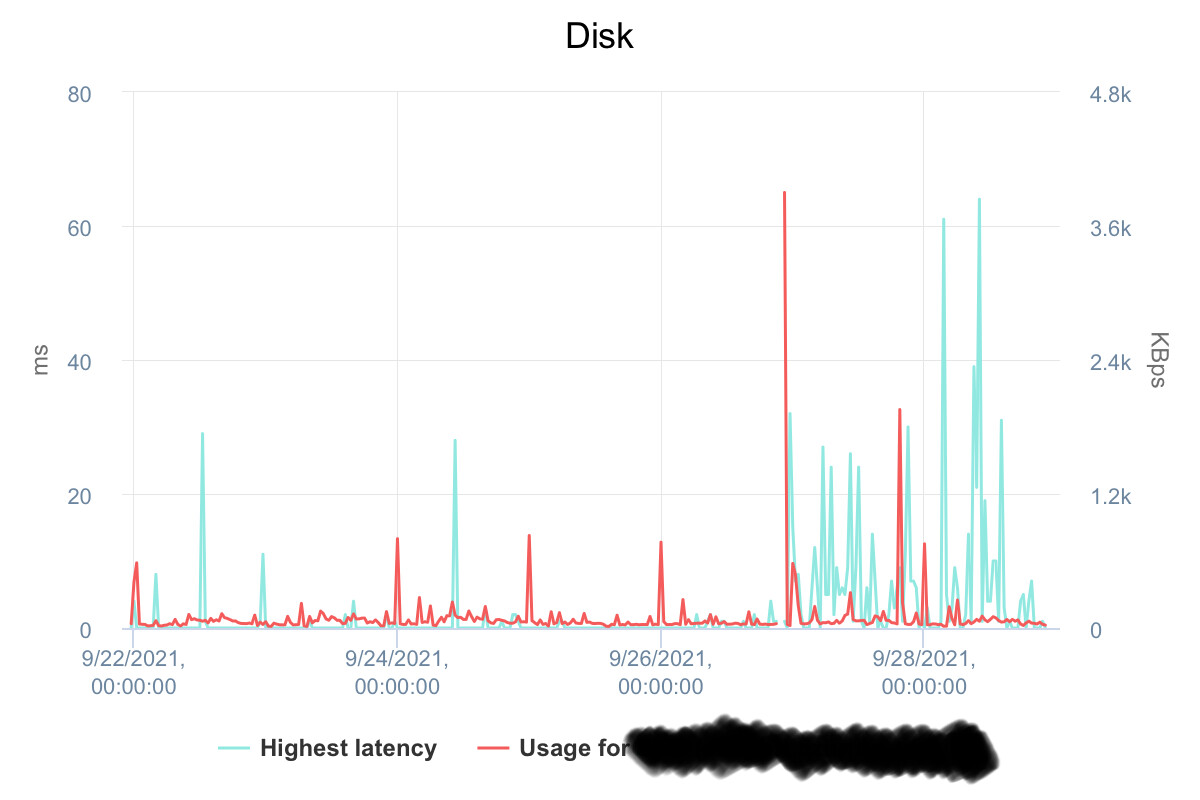
The top capture shows a system which is barely under load (but this is only a snapshot). The disk latency graph shows the problem (if I’m reading it correctly). The frequent ~20ms delays, with spikes to 40ms and up to 60ms would be very noticeable on the system and indicate storage performance issues. You should probably focus on that.
Thanks, I am looking into this on our NAS.
I wonder why Zammad is so sensitive to latency (our other services are running fine on the same setup) - is it because of Elasticsearch needing constant/frequent access to HDD?
Your performance may be poor if you haven’t tuned Zammad out of the box. This can become more apparent after you’ve hit a certain number of tickets in your setup, or simultaneous agents working on those tickets. Your really should look into performance tuning and start by gathering metrics on CPU usage, load, disk I/O, network traffic, etc. The basics. Monitoring the database might be a good start, as it is constantly being used on a busy system. If it is improperly tuned, most of that I/O might hit the disks instead of RAM, killing performance, unless you have a very high performance storage backend.
Thanks Dennis. We have ordered an MVNe PCI card to be used as buffer on the NAS. We’ll see how this affects overall perf.
To be honest my “naive” approach was that, because we only have 3/4 concurrent access, tuning wasn’t critical. But I’ll follow your advice and look into this after the NAS has been upgraded.
Quick update, and hopefully some insight for people facing similar behavior:
The ssd cache did help a little, but I was still seing high latency that translated into slow GUI.
So I looked into vSphere documentation and realize the SCSI controller I was using for the Zammad VM wasn’t perhaps the best one → Changed to ‘VMware Paravirtual SCSI’, and the latency totally went down (less than 10ms)…
It could have been the end of if, but unfortunately the overall system is still very slow.
Here is my config: 16 Cores, 16 Gb of RAM, 500 Gb HDD
One of the most frustrating behavior is logging in the system, and having to wait 10s in front of a white page, before the Zammad GUI would show…
What I’ve said before and what you seem to be ignoring: start by monitoring the basics. Start by graphing performance metrics over time, inside the OS as well as at the hypervisor level. I’m guessing your VM packs a bit of a punch, but the software just isn’t using all that power because it isn’t tuned appropriately. Adding RAM does nothing if you aren’t configuring your applications to actually use it. Giving the VM a lot of CPU’s does nothing if the applications aren’t instructed to start more worker threads to distribute the load. Performance metrics will probably point to a possible problem area to focus on, allowing for some quick wins.
What is the output of this database query? SELECT * FROM pg_settings WHERE source != 'default';
What is the output of this shell command (run while the system is feeling sluggish): zammad run rails r 'p Delayed::Job.count'
What is the output of these shell commands? zammad config:get WEB_CONCURRENCY zammad config:get ZAMMAD_SESSION_JOBS_CONCURRENT
I have the same impression: the power isn’t used by the VM.
Please see bellow the output of the database:
name
setting
unit
application_name
pgAdmin 4 - CONN:4532221
NULL
bytea_output
hex
NULL
client_encoding
UNICODE
NULL
client_min_messages
notice
NULL
cluster_name
12/main
NULL
data_checksums
off
NULL
DateStyle
ISO, MDY
NULL
default_text_search_config
pg_catalog.english
NULL
dynamic_shared_memory_type
posix
NULL
lc_collate
en_US.UTF-8
NULL
lc_ctype
en_US.UTF-8
NULL
lc_messages
en_US.UTF-8
NULL
lc_monetary
en_US.UTF-8
NULL
lc_numeric
en_US.UTF-8
NULL
lc_time
en_US.UTF-8
NULL
listen_addresses
*
NULL
log_line_prefix
%m [%p] %q%u@%d
NULL
log_timezone
Etc/UTC
NULL
max_connections
2000
NULL
max_stack_depth
5120
kB
max_wal_size
1024
MB
min_wal_size
80
MB
port
5432
NULL
server_encoding
UTF8
NULL
shared_buffers
262144
8kB
ssl
on
NULL
ssl_cert_file
/etc/ssl/certs/ssl-cert-snakeoil.pem
NULL
ssl_key_file
/etc/ssl/private/ssl-cert-snakeoil.key
NULL
temp_buffers
32768
8kB
TimeZone
Etc/UTC
NULL
transaction_deferrable
off
NULL
transaction_isolation
read committed
NULL
transaction_read_only
off
NULL
wal_buffers
2048
8kB
wal_segment_size
16777216
B
work_mem
10240
kB
run rails r ‘p Delayed::Job.count’ → returned 0 zammad config:get WEB_CONCURRENCY → returned nothing zammad config:get ZAMMAD_SESSION_JOBS_CONCURRENT → returned nothing