Used Zammad installation source: (source, package, …) package
Operating system: Debian 9
Browser + version: Firefox
Hello,
We are having an issue with Zammads memory usage. We noticed it after setting WEB_CONCURRENCY to 4 and increasing max-connections in postgress.
Our hardware is 1 CPU 4 cores.
12 GB RAM
~50 Agents
~30 Groups with 2 Overviews each
~1000 tickets
~15 agents working on peak time
Storage mechanism is set to Filesystem in Zammad->Admin->System->Storage
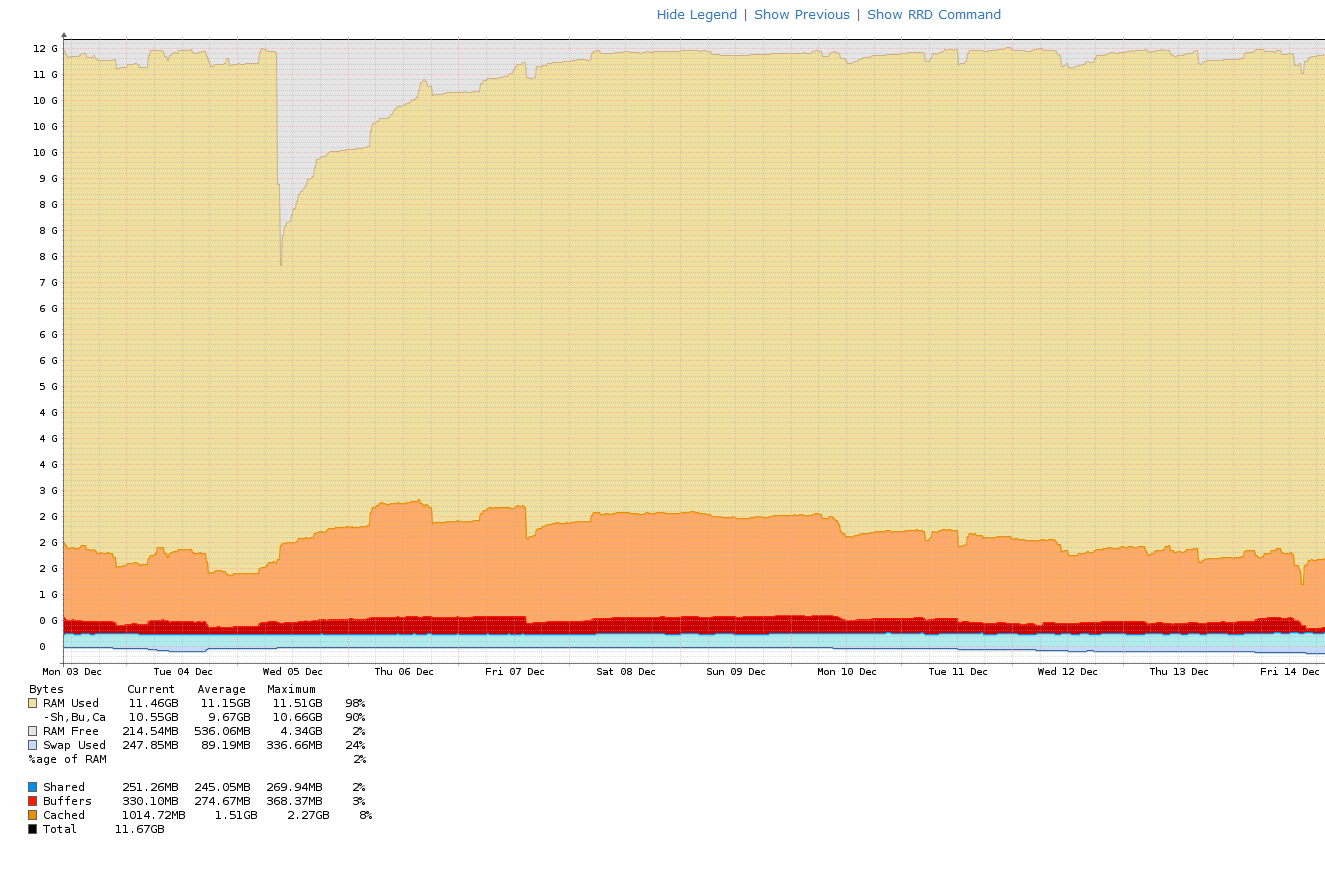
It looks like a memory leak on first glance as after reboot the system starts at around 50-60 % memory used and then creeps up to >90% memory usage within 3 days. After the max memory limit is reached it starts using more of cached memory which gets thinner and thinner until swap comes in.
The following graph shows this behaviour:
On December 5th we rebooted the system and the memory usage was rising constantly for over a week until swap started to be used.
This is of course unwanted behaviour and it would be great to get some insight here what is happening.
Is this some setup/config issue? Should we allocate more memory?
On the other hand what speaks against a setup issue is that it takes 3 days to reach nearly 100% memory usage. If the hardware was not scaled well I would expect it to reach the maximum memory much faster.
Or is this some garbage collector working to slow?
Any hints are appreciated.
This rather sounds like elasticsearch eating up all the RAM to be honest.
A sole graph like above doesn’t help you finding the issue, you need to know what processes take how much memory.
You can limit the memory usuage of elasticsearch (you really should), as it will take everything for caching it get. PGSQL does also use RAM for caching stuff, but that shouldn’t be too much against ES.
If your machine starts using swap it’s a good indication that something needs more RAM as it gets.
Zammad shouldn’t be the cause here.
I’d limit elasticsearch to 4GB.
You can play around with those values to find a suitable solution for you, as my opinion isn’t always absolutely correct.
the usage pattern you’re seeing is normal, with used memory starting low and rising with use over time. 95% memory use doesn’t mean there’s only 5% of memory available. I have a rough idea of how memory is managed in linux but I wouldn’t be able to describe it with 100% accuracy, so see if you can google for a description.
A bit more information from our side. We checked the elasticsearch config and it is already limited to a heap size of 2 GB. Looking at top this also fits to what we are seeing. elasticsearch process takes ~2.7 GB which is alright. Several Postgress processes are using ~4 GB which is also fine for our config.
However checking with netdata tool we see that the puma process is taking nearly 6 GB. A little google search later we see that puma is the webserver process for Zammad/Ruby.
Could you elaborate on why puma process is using ~50% of our RAM and why it is constantly using more?
Is this some stuck garbage collection or similar?
@chesty Yes we are aware that Linux calculates mem usage weirdly in some cases, but here 11 out of 12 GB are actually in use, not buffered or cached, in use. Also swap is starting to fill up which indicates that there is no more space in RAM left. So we currently doubt that it is a display error.
Maybe web_concurrency=4 is a bit much for only 4 cores?
Doesn’t address the RAM usuage, but might lead to performance issues (as you got other stuff that needs some steam too)
Maybe @anon29869905 has an idea regarding the memory usuage of PUMA.
So the first two malloc values are already the same.
The last two are even lower than the ones suggested. Wouldn’t that mean that it would do garbage collection even more often or do I misinterpret that values here? Would changing it to the ones suggested make a difference?
How are MIN and MAX Threads to be interpreted? Actual number of available CPU threads or threads in the sense that Zammad can open up to x threads on the OS for processing?
We now tested what happens with the system if RAM runs out…
The result is not pleasing. Basically all “unnecessary” processes get dropped. About 70% of all postgress processes were dropped and elasticsearch was killed completely leaving the search GUI unresponsive and Zammad was not able to query Users or Tickets from the GUI. Swap was filled only by 40%.
Luckily incoming tickets were not blocked as postgress was still running. Very low, but still running so nothing was lost.
Our “Workaround” is to restart the server daily with a cronjob… this is not great but the only way we see having a stable system at the moment.
We would really appreciate if you could guide us with a proper setup here so we do not risk getting a RAM overflow after ~1 week.
That’s a very bad workaround / solution and doesn’t solve any problems.
If this really is a Zammad issue, this needs testing as this might strike any one.
Problem is, dozens of people use Zammad in productive with even more concurrent active agents.
Small hint regarding killing of processes: This is a linux behavior you can configure.
And another thing: You should always try to avoid to use swap, as your systems performance will decrease significantly.
How many max_connection does your PGSQL allow? Sounds like you’re allowing too much RAM somewhere.
However these two changes started the slow but constant increase of memory usage.
Do they have regular maintenance periods where servers or services might be restarted?
Or do they have 0 maintenance 100% uptime setups?
Fair enough, but it should have never gotten to that point. The swappiness of the system is currently set to start using swap if less than 10% memory are available.
if this happened after increasing max_connections it could be postgres is configured to use more memory than available, but not necessarily, it might be web_concurrency making the difference whereas previously it was limited to roughly 100 threads that could open a connection to postgres, now there’s no such limit.
I would confirm postgres can’t use more than “(total memory - elasticsearch memory) / 2” with max_connections full, and then lower MAX_THREADS, maybe halve it. This is just me experimenting, making a change that makes sense without knowing for sure what the exact problem is.
Thank you for the input.
We will try out some of the suggestions. psql has currently ~150 processes running on average, so lifting it to 200 was definitely the right move.
However testing different parameters is a bit tedious, as we can only say after 4-5 days of running if we are running into a memory issue again or if memory usage plateaus.
Over Christmas holidays we will stick with the reset strategy and try different setups after our IT team is complete again after holidays.
We will try setting MAX_THREADS to a lower number first and see if it makes a difference.
If not we will check the psql conf and try to fine tune it.
Any other suggestions are welcome as well.
The way I see it is you’re going to have to restart every few days until it’s fixed anyway, so adjusting MAX_THREADS in the blind wouldn’t be a problem for me, I’d do it and see what happens.
All it going to do is lower the max amount of memory rails will use, I’m assuming the more threads the more memory it can use. It will still start low and grow over time, but this time it the potential max it could grow to will be lower. I don’t think the growing memory use is definitely a memory leak.
Also whatever created that graph you posted might be able to create graphs of processes and threads, you might be able narrow down exactly where the memory is being used. If not, you can use the ps command.
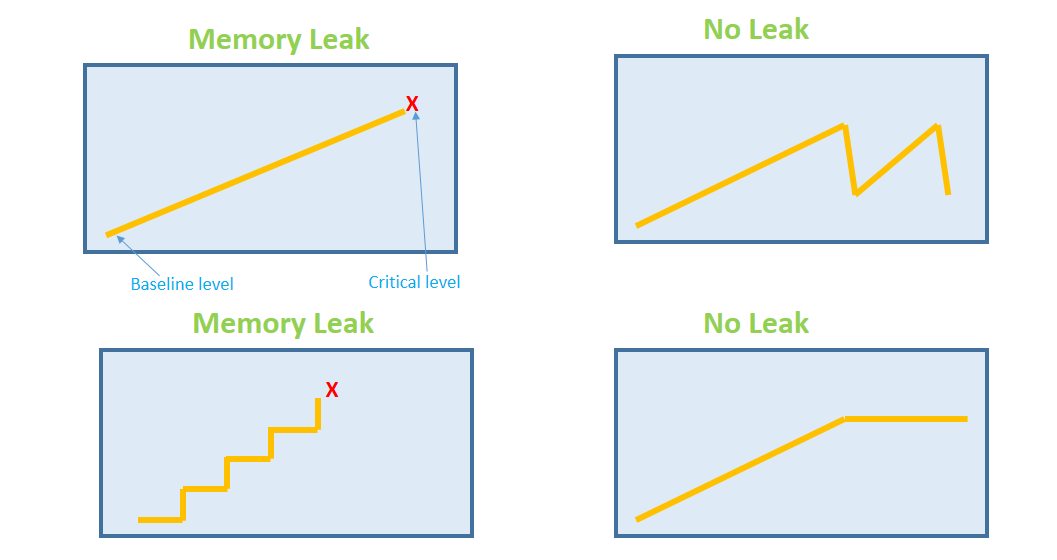
The thing is that this probably not memory leak per definition. A memory leak is indicated by a continuous and steep rise of memory. Here is a picture that shows it pretty well:
While it’s not exactly the same as yours - the image in the lower right is what we face here. We already analyzed this earlier for one of our customers and found out that Rails holds on to the ActiveRecord instances created (which are quite a few in your system, according to the key figures you provided). We then found the ENVs posted earlier and they did the trick for us/the customer. Since then we used/recommended them a couple of times and they did their job.
So I think the question is more of why the ENVs aren’t working as expected. I think it’s the combination of WEB_CONCURRENCY=4 and the 2GB RAM limit per ruby process. Quick math: 4*2 = 8. This means that your Puma process is allowed to take 8 GB of RAM + 2 GB for the Scheduler and 2 GB for the Websocket server which makes a sum of 12 GB of RAM allowed for only the Ruby processes - elasticsearch and postresql not included
Conclusion: Could you please try to limit the allowed memory size to 1 oder 1.5 GB of RAM via the ENVs?
Thank you for your answer.
For clarification with what ENV can I set this limit?
Is it one of these?
MIN_THREADS=“6”
MAX_THREADS=“30”
RUBY_GC_MALLOC_LIMIT=“1077216”
RUBY_GC_MALLOC_LIMIT_MAX=“2177216”
RUBY_GC_OLDMALLOC_LIMIT=“2177216”
RUBY_GC_OLDMALLOC_LIMIT_MAX=“3000100”
Hi @SEGGER-NV - sorry for my late response. We had some technical internal issues I needed to resolve first. However, I can only tell you from our experience. We maintain systems with a similar or bigger size than yours with that ENVs set without (memory) problems. As mentioned earlier after applying these back then when we faced memory issues these resolved. I’m afraid I can’t help you any further in the scope of free community support because this seems to be a specific error with your installation/setup. We focus our community work to resolve issues that affect the majority. However, we’re happy to help you with our commercial enterprise services.
This is quite a weird statement as you wrote earlier:
So this statement raised the questions:
Which ENVs exactly?
Where do you get your “quick math” values from?
Is this somewhere documented?
Could you answer these as it seems like that information would be quite valued in the community seeing all the threads pop up discussing server setups?
It is weird that you tease an “obviously simple answer” and then not to specify it. At least that is the vibe I got from that post.
I don’t mind getting my hands dirty, but I would like to know what I am up against without an avoidable trial & error spiral.