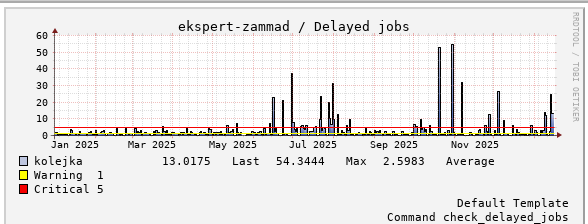
Hey @Dr4gon ,
I conducted an extensive verification of the situation regarding Zammad, and it appears that the issues actually started in June 2025. According to the change log, the problems correlate precisely with the update to Zammad version 6.5. Specifically, on 2025‑06‑13 the system was updated from version 6.4.1 to 6.5.
Start-Date: 2025-06-12 19:32:19
Upgrade: zammad:amd64 (6.4.1-1740041753.d1854e51.bookworm, 6.5.0-1749747762.06d0d09c.bookworm), elasticsearch:amd64 (7.17.27, 7.17.28)
Start-Date: 2025-06-16 21:13:39
Commandline: apt upgrade
Upgrade: zammad:amd64 (6.5.0-1749747762.06d0d09c.bookworm, 6.5.0-1750081170.05c943c2.bookworm)
Start-Date: 2025-06-30 18:31:32
Upgrade: zammad:amd64 (6.5.0-1750081170.05c943c2.bookworm, 6.5.0-1751286427.c7b49f45.bookworm)
Start-Date: 2025-07-17 16:39:16
Upgrade: zammad:amd64 (6.5.0-1751286427.c7b49f45.bookworm, 6.5.0-1752675208.6878f0d2.bookworm)
Start-Date: 2025-08-27 07:08:54
Commandline: apt-get upgrade
Upgrade: zammad:amd64 (6.5.0-1752675208.6878f0d2.bookworm, 6.5.1-1755869083.a659a77f.bookworm)
Start-Date: 2025-08-27 07:08:54
Commandline: apt-get upgrade
Upgrade: zammad:amd64 (6.5.0-1752675208.6878f0d2.bookworm, 6.5.1-1755869083.a659a77f.bookworm)
Start-Date: 2025-09-14 07:51:31
Upgrade: zammad:amd64 (6.5.1-1755869083.a659a77f.bookworm, 6.5.1-1757685677.3b34f3d9.bookworm)
Start-Date: 2025-09-28 15:57:24
Upgrade: zammad:amd64 (6.5.1-1757685677.3b34f3d9.bookworm, 6.5.2-1758956852.cb9e869e.bookworm)
Start-Date: 2025-12-17 17:41:42
Upgrade: zammad:amd64 (6.5.2-1758956852.cb9e869e.bookworm, 6.5.2-1765903927.5697ef96.bookworm), telegraf:amd64 (1.36.2-1, 1.37.0-1)
I also reviewed the monitoring data more broadly, and after an internal discussion of the current situation, we confirmed that the changes I introduced in November and the recent adjustments have no impact on the scheduler errors.