we have 4 Zammad systems running, each on a separate V-Server. All have similar hardware and similar usage. Similar configuration etc.
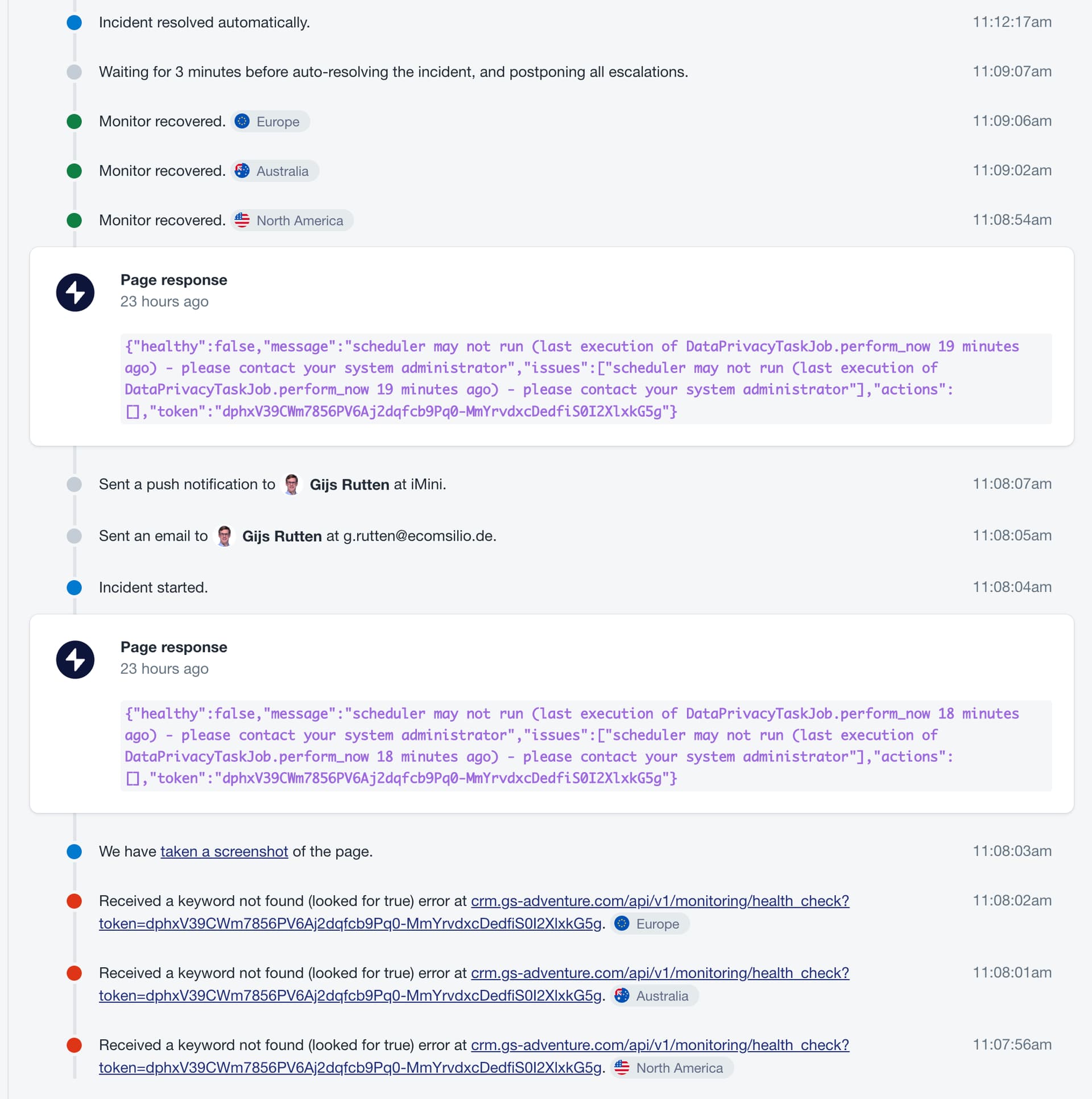
We have updated from version 5.0.3 to version 5.2.1 just last week and since then we have the following error, but only on 2 of the machines. The other 2 don’t have this error.
scheduler may not run (last execution of Stats.generate 20 minutes ago)
or
scheduler may not run (last execution of DataPrivacyTaskJob.perform_now 18 minutes ago)
Each time the error just disappears within 1-2 minutes. So there basically is no issue but since we monitor zammad’s health status, each time the health status≠true, our monitoring alarm rings.
I have checked logs:
production.log - no errors
scheduler_err.log - empty
scheduler_out.log - empty
searchindex-rebuild.log - empty
elasticsearch.log - empty
Which other logs can I check? Do you have any tips where to look for more details on why the scheduler does not work for around 20 min?
This is from the production.log
It is not an error or a warning but it might help to find a reason for the scheduler not running or running “late”.
I, [2022-08-02T00:33:47.248853 #89012-1238800] INFO -- : execute Stats.generate (try_count 0)...
I, [2022-08-02T00:33:47.533274 #89012-1238800] INFO -- : ended Stats.generate took: 0.292728832 seconds.
I, [2022-08-02T00:33:50.790962 #89012-109280] INFO -- : 2022-08-02T00:33:50+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [3d46142f-8d3d-4508-850c-dd635ca37925] from DelayedJob(default) with arguments: ["StatsStore", 7] (id=169979) (queue=default) RUNNING
I, [2022-08-02T00:33:51.113387 #89012-109280] INFO -- : 2022-08-02T00:33:51+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [3d46142f-8d3d-4508-850c-dd635ca37925] from DelayedJob(default) with arguments: ["StatsStore", 7] (id=169979) (queue=default) COMPLETED after 0.3223
I, [2022-08-02T00:33:51.116133 #89012-109280] INFO -- : 2022-08-02T00:33:51+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [a1517a5f-f355-48db-895a-f866108b0965] from DelayedJob(default) with arguments: ["StatsStore", 1] (id=169980) (queue=default) RUNNING
I, [2022-08-02T00:33:51.202231 #89012-109280] INFO -- : 2022-08-02T00:33:51+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [a1517a5f-f355-48db-895a-f866108b0965] from DelayedJob(default) with arguments: ["StatsStore", 1] (id=169980) (queue=default) COMPLETED after 0.0860
I, [2022-08-02T00:33:51.204621 #89012-109280] INFO -- : 2022-08-02T00:33:51+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [31af75a1-6a10-4a72-8caf-561f2a0a4ceb] from DelayedJob(default) with arguments: ["StatsStore", 5] (id=169981) (queue=default) RUNNING
I, [2022-08-02T00:33:51.526409 #89012-109280] INFO -- : 2022-08-02T00:33:51+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [31af75a1-6a10-4a72-8caf-561f2a0a4ceb] from DelayedJob(default) with arguments: ["StatsStore", 5] (id=169981) (queue=default) COMPLETED after 0.3217
I, [2022-08-02T00:33:51.529036 #89012-109280] INFO -- : 2022-08-02T00:33:51+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [1fbe5a89-80ee-4e76-86ad-7078886006f9] from DelayedJob(default) with arguments: ["StatsStore", 6] (id=169982) (queue=default) RUNNING
I, [2022-08-02T00:33:51.620575 #89012-109280] INFO -- : 2022-08-02T00:33:51+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [1fbe5a89-80ee-4e76-86ad-7078886006f9] from DelayedJob(default) with arguments: ["StatsStore", 6] (id=169982) (queue=default) COMPLETED after 0.0914
I, [2022-08-02T00:33:51.623795 #89012-109280] INFO -- : 2022-08-02T00:33:51+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [e11bba9c-d628-465a-a7b7-87eeaa4685ea] from DelayedJob(default) with arguments: ["StatsStore", 9] (id=169983) (queue=default) RUNNING
I, [2022-08-02T00:33:51.723300 #89012-109280] INFO -- : 2022-08-02T00:33:51+0200: [Worker(host:crm.gs-adventure.com pid:89012)] Job SearchIndexAssociationsJob [e11bba9c-d628-465a-a7b7-87eeaa4685ea] from DelayedJob(default) with arguments: ["StatsStore", 9] (id=169983) (queue=default) COMPLETED after 0.0994
I, [2022-08-02T00:33:55.400977 #89012-718820] INFO -- : execute Channel.fetch (try_count 0)...
I, [2022-08-02T00:33:55.402858 #89012-718820] INFO -- : ended Channel.fetch took: 0.008868718 seconds.
The error now occurs on all 4 machines. Most of the time, the error only appears 1 or 2 times a day. The error disappears automatically within 60 seconds.
But why does this error eppear in the first place. Please let me know what else I can check?!
I have changed the info level to debug and hereis 1 log file (part of it).
Some scheduler jobs are expected to run in a specific time frame. If that time frame is left, Zammad will point that out as when fetching the monitoring endpoint (or having a look within the UI). If the task runs in the mean time the issue may self heal - given that the task was run successful.
Usually background-services (was scheduler before) has plenty of head room to meet above mentioned expectation. However, in some load situations it may no longer meet these expectations. This can have various reasons: e.g. you have fairly high concurrent users in the system at that time or have a lot background tasks going on.
Theoretically your process list should show that. If background-services.rb is running sticky at 100% that’s a very good indicator for said situation. If that’s the case you’ll want to begin performance tuning as that’s the only way to overcome this issue technically.
There’s no general recipe for this task I’m afraid. It’s rather fiddling. Note that Zammad 5.2 actually came with new tuning options additional to the existing ones. You can pull apart background tasks even more.