es_attachment_ignore: Extendet with frequently used useless files
es_attachment_max_size_in_mb: 5mb
Expected behavior:
Seamless user experience
Actual behavior:
Some of our tickets are very large, with lot of inline pictures and attachments.
There is one extra large ticket. When this ticket receives a change, it takes several minutes to update the elastic index. At this time, there is one single background worker which is up to 100% cpu all the time.
During this time, zammad is very slow in general and some other task are delayed for several minutes. For example, if a new ticket has been created it takes a couple minutes until it is available via api.
Steps to reproduce the behavior:
Deal with a very large ticket.
Actually there is one other app running on the same server, what makes me very cautious with performance tuning.
In these days, I will receive an additional 6 cores and move the other app to another server.
Question
Regarding the large size of tickets, can someone give a recommendation on which change makes the most sense for this problem?
Please let me know if I should provide more information.
I can’t give you a solution for your problem, but you could just try splitting the ticket into a new one? That way you might be able to speed up the work until the cause for the performance issue is resolved.
Have you had a look at your processes in these situations?
Generally “everything goes slow” sounds like a host issue to be frank. Updating the search index has nothing to do with web interface interaction and thus shouldn’t be affected at all.
There are no issues with the host; the other application operates perfectly. Zammad also runs properly unless this particular situation arises.
I think the reason why the web interface also becomes slower is that this ticket has many subscribers. When the ticket receives an update and the subscribers get a notification, and many of them open the ticket simultaneously, a bottleneck occurs because the ticket has become very large, and the entire content is downloaded to the client.
I can live with that; it is just a bit slower but has no side effects.
At the same time, the background task for the elastic index update is also started and runs in parallel for at least 5 minutes. During this time, other jobs are obviously delayed, like sending and fetching mails or triggering and executing web hooks.
What bothers me the most is that new tickets or changes to existing tickets are not available via the API during this time.
If anyone has experience with this, they are welcome to share it with me; otherwise, I will explore it step by step.
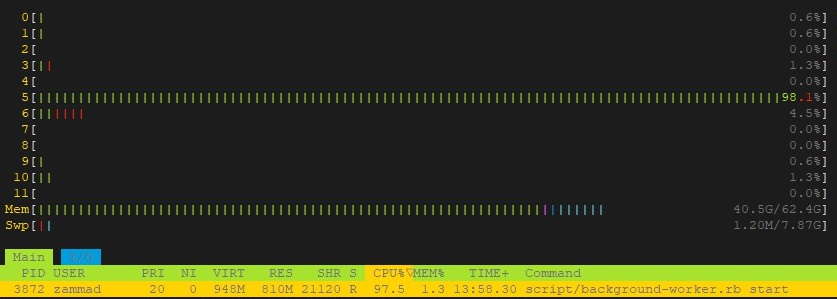
I made a manual ticket update now.
The delayed job count before was at 0.
On the image below, you can see the job counts of the next 30 minutes after the ticket update.
First print was after 4 minutes, then approx. 1 print per minute.
Sometihng doesn’t add up in your descriptions I’m afraid.
Maybe using one delayed job worker (or two) helps, but I guess the actual problem is your web concurrency. If I’d had to guess, the slow UI issue is somewhat of a “coincidence” when the index stuff is running. Just a guess though.
Maybe this shameless video might help you too, for the bigger image: