Infos:
- Used Zammad version: 6.2.0-1704877727.2bda00c4.bookworm
- Used Zammad installation type: PPA-Packages
- Operating system: Debian 12
- Browser + version: Chrome newest Version
We started hosting Zammad at AWS according to your documentation on a t3a.medium (2 vCPUs with 4.0 GiB) EC2-instance with a postgreSQL on a db.t4g.medium (2 vCPUs with 4 GiB) RDS-instance last year. Sometime in Q4/2023 we started duplicating parts of our incoming support mails into Zammad to get feedback from our employees on how to best configure the software for their workflow. Some time after these initial steps on Zammad, we started experiencing performance issues which prompted us to install Elasticsearch and upgrade the EC2 instance to t3a.large (2 vCPUs with 8.0 GiB) as you recommended. This helped, but the feedback from our test staff was still not really positive in terms of performance.
We have now gradually upgraded the instance to a t3a.2xlarge (8 vCPUs with 32.0 GiB) EC2 instance with a db.t4g.large (4 vCPUs with 16 GiB) RDS instance and still have occasional wait times of up to 2 minutes. On the RDS instance for the postgreSQL DB, we did not notice any load peaks. On the EC2 instance, on the other hand, we repeatedly have spikes in utilization even when idle.
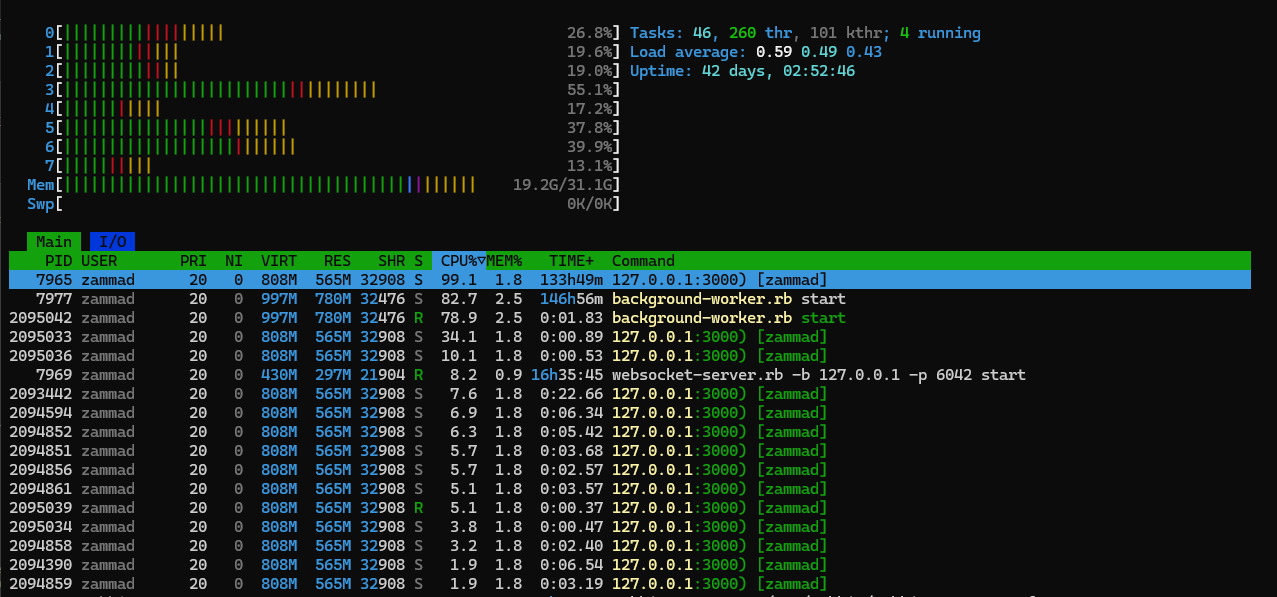
To date, around 9 months later, our automatically incrementing ID of the ticket table is just under 6000 and the number of employees working in parallel on the system is in the lower single-digit range. Unfortunately, we cannot explain how this immense consumption of resources comes about and would be grateful for any help.