I would expect the overviews and notifications are updated, when something changes
Actual behavior:
Overviews and notifications aren’t updated when the browser is connected to the websocket (domain:port/ws) endpoint. However everything seems to update fine when using je ajax client. I’ve tested this by blocking the websocket call;
I’ve seen several issues in this community regarding not updating overviews, but these seems to be related to performance issues in the scheduler, but i don’t see any pending jobs, and most tasks complete within a second. Also the cpu usage is minimal, and we don’t have large overviews (largest containing around 20 items)
Also i notice i do receive a lot of Content Security Error’s i’m not sure if that is related;
I don’t really know how to reproduce this issue, except connecting through the websocket.
I suspect it has something to do with my installation, but i wouldn’t know what, and how to debug this further. So any pointers are welcome.
One suspicion is that the websocket service create’s socket files in the tmp/websocket_production/* directory, i’m not sure where these are used for.
This indicates that your webserver does either not support websockets or fails to answer in time for whatever reason. If you have a proxy server in front of your docker-compose stack, ensure that it also supports websockets and routes it cleanly to the docker-compose.
Zammad falls back to Ajax-Longpolling to still enable your users to get close to realtime updates.
It’s not Zammad related, check your webserver logs which may help with finding the issue.
This can be a normal error.
This usually happens if you run Zammad for a very long time without reload and collected that much data that it’s getting too much for the Browser. (Browsers limit the local storage for various reasons).
Reloading should help to make this message disappear.
If not, you possibly have a fairly big ticket with big images and stuff and you’re loading which could lead to this issue.
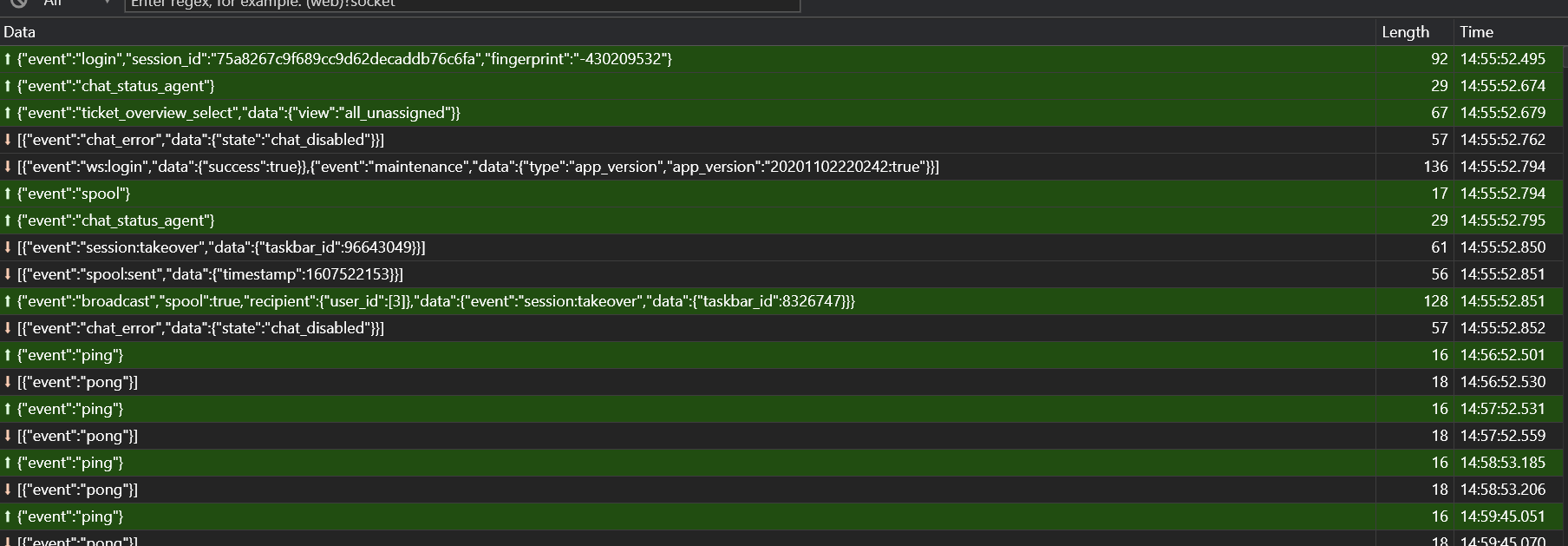
The first screenshot is just to indicate how i tested this without using the websocket, thus where i deliberately disabled the websocket. The Second screenshot is of the messages send back and forwarded on the /ws endpoint from the chrome debugger (thus when the websocket is available and the browser is able to connect). Also i don’t see that that the service is slow, if you check the ping/pong timestamps you see the service response in ~30ms. The thing is the only messages i see are the ping/pong messages, besides the initial messages, and i see message’s after a user interaction (e.g. navigating to a new overview). But i never see that the /ws sends new information/data initiated by the websocket server. I think that’s the issue, but i don’t know why the websocket server never sends update’s. I don’t have a reverse proxy in front of my stack, so we can rule that out.
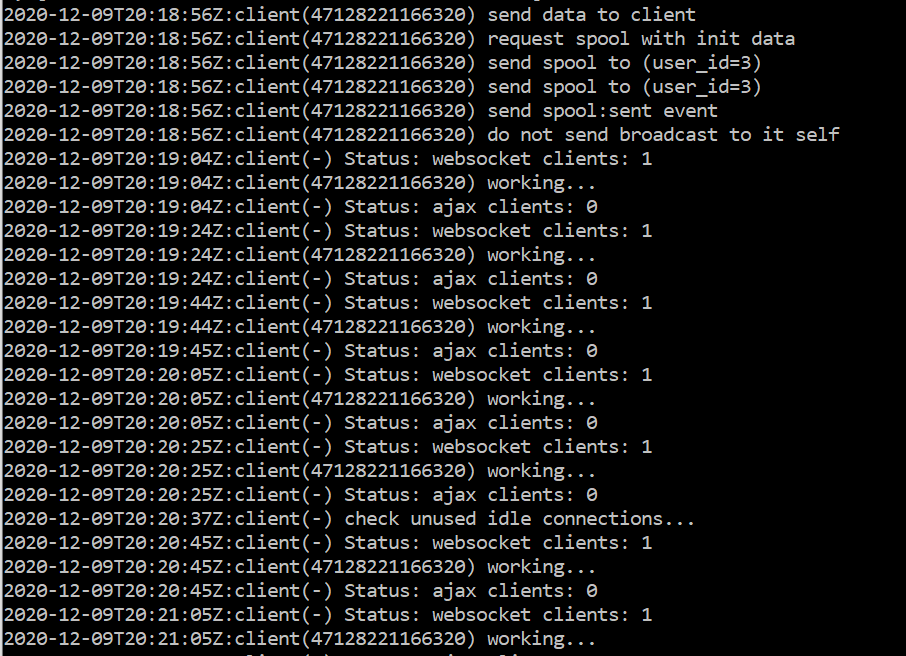
Sorry wrong phrasing, these are logs of the websocket service, which logs about every 15 seconds this;
2020-12-30T12:31:34Z:client(47032937627280) working…
2020-12-30T12:31:34Z:client(-) Status: ajax clients: 0
2020-12-30T12:31:54Z:client(-) Status: websocket clients: 1
Thus also indicating the websocket service acknowledges it has a connected websocket client. But not logging any error’s on why it might not push new information to the connected websocket client.
I’ve these error’s directly after refreshing. visually i don’t see anything broken or missing images.
it is related to this response header;
Maybe it doesn’t like i’m not running on a standard port.
I’m not sure where the localStorage error is coming from. I even receive it when i clear all storage data. Inspecting the localStorage i see other tickets stored, maybe the ticket it tries to store has a too long value.
but i suspect the localStorage and content security errors are unrelated to this specific issue. I just thought maybe it’s helpfull related information.
Any information on gathering more information on what the websocket service is doing, and when it’s pushing new information to the client. would be appreciated.
As soon as Zammad is in Ajax-Fallback-Mode it will never try websockets again unless you reload the application. This is why you’ll never receive push updates by websocket connections.
It should be safe to ignore this error.
The reason for that may be that you’re opening fairly big tickets from the beginning.
Zammad caches all data upon initial loading. It will only fetch new / changed data if needed (by e.g. opening a new ticket). This is the reason why the UI usually is blazingly fast.
I don’t see any reasons why you shouldn’t receive new data. No matter if by Fallback or Websocket.
Maybe run this on a rails console (zammad run rails c):
You mean with this just refresh the browser? If yes, i’ve refreshed the browser in between the tests, and i can confirm the browser connects to the websocket, and maintains a connection, since it’s listed in the network tab, and i see ping/pong message’s flowing.
I’ve the same question, i would like to know. Via the fallback it’s working fine, via the websocket it’s not, and i don’t understand why. And don’t know how to debug this further. So help is appreciated
I suspect it has something todo with the socket files the websocket service creates;
/tmp/websocket/websocket_production/
But i’m unsure.
i see these files;
ls -la tmp/websocket/websocket_production/47001812929700/
-rw-r–r–. 1 1000 hugetlbfs 68 Jan 11 17:00 session
ls -la tmp/websocket/websocket_production/spool/
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 09:44 1610358267.951105-97803
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 11:35 1610364944.8374946-57691
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 12:13 1610367223.5424373-19177
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 12:39 1610368745.65312-77242
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 12:39 1610368777.2985005-67725
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 13:18 1610371127.773438-40984
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 13:41 1610372503.7901158-95390
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 16:17 1610381849.816423-39055
-rw-r–r–. 1 1000 hugetlbfs 181 Jan 11 16:28 1610382485.825334-80817
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 16:29 1610382570.9167738-88076
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 16:29 1610382599.9309022-9381
-rw-r–r–. 1 1000 hugetlbfs 182 Jan 11 16:36 1610383016.1506007-43611
root@4959ee30aec1:/opt/zammad# rails r ‘p Scheduler.where(active: false).pluck(:name)’
I, [2021-01-11T16:49:54.397513 #286-47286979565940] INFO – : Setting.set(‘models_searchable’, [“Chat::Session”, “KnowledgeBase::Answer::Translation”, “Organization”, “Ticket”, “User”])
seems thus to return an empty array
scheduler process is running idle (about 0.03% cpu usage), with sometimes a spike to about 4%
oke, i think i figured it out. But please correct me if i’m wrong.
It seems the railserver is writing send-xxx json files to the tmp/websocket_production directory, which are being read by the websocket service. Since in my setup i separated the /tmp directories per container, due to the fact the /cache folders are cleared on startup, causing missing files error and other strange behaviours for each container. The tmp/websocket_production directory needs to be shared between the railserver, websocket and scheduler service. While i tried this before it also seems (since i’m using gluster (v7) as storage backend), the volume needs to be configured with certain properties, otherwise it doesn’t work.
i can seen now at least how an update from the server looks like;
from gluster perspective, these are the gluster volume properties that seems to work only;
Options Reconfigured:
performance.client-io-threads: off
nfs.disable: on
transport.address-family: inet
network.remote-dio: off
performance.strict-o-direct: on
cluster.choose-local: off
cluster.brick-multiplex: on
As soon as you see “ping pong” messages within the network tab, the websocket connection is not working on the client. If you see ping pong, the Ajax Fallback runs.
Sorry but my help is limitted.
Ensure that - if it does not affect all clients, websocket connections are not lost on the way to the user. The reason for that can be a firewall or your docker setup itself.
That’s more like we expect to see.
You’re right.
The containers have a shared storage which is needed to workaround Zammad not being entirely “stateless”.
Yes and no.
You can run zammad run rake routes to list all available routes.
The listing will, beside the path, also tell you the methods to use (POST / GET as example) and which controller is responsible. From this point it’s either trial and error (if not documented) or looking it up within source code.
My tip would be to use the GET endpoints first.
This helps to get an idea what kind of data you get - if you know what you get, you also have a good chance to know what the endpoint expects.
Thank you for your reply, but this rake command will show all available HTTP requests. But i’m looking for the shared storage paths, used by the containers.
How i see this, there are 3 “main” containers; railsserver, scheduler and websocket.
railserver;
/tmp [needs to be private]
/tmp/cache [needs to be private]
/tmp/websocket_production [needs to be shared]
/tmp/sockets [unknown]
/tmp/pids [unknown]
websocket;
/tmp [needs to be private]
/tmp/cache [needs to be private]
/tmp/websocket_production [needs to be shared]
scheduler;
/tmp [needs to be private]
/tmp/cache [needs to be private]
/tmp/websocket_production [needs to be shared]
Just to state the obvious, the data directory needs to be shared with all containers
@olafbuitelaar Thanks for finding this out. I am now sharing the tmp/websocket_production directory on my servers using s3fs. Finally, live updates seem to be working correctly in our docker swarm-based setup.
That said, there should probably a more scalable to this solution. Maybe use memcache / redis for this in the future? (EDIT: Or just use the database…?)
@lorn I agree, probably the database/redis would better suffice for this. But maybe they some filesystem events they subscribe to, in that case they would need some kind of trigger based database, which of course postgres has. But some alternative’s like zookeeper could work as well.
And glad to hear it’s solved for you case as well. For me it’s seems a bit on and off, but generally it seems to be working. But that could still have other causes.
As the project seems to support multiple database systems, postgres-specific features cannot be used. I think in order to keep the number of servies low it would make sense to replace memcached with redis and use redis as a cache store as well as a queue. Or even have both memcached and redis running in parallel.
I had a look at the code. It seems to be quite straightforward to implement, since the whole logic seems be encapsulated in the sessions.rb module. That could be completely replaced. Alternatively, the new queueing strategy could be implemented as an optional replacement.
EDIT: Using ActionCable would even allow making the queuing backend exchangeable.
Would the Zammad maintainers be interested in such an implementation?
well mysql also supports triggers as well. But personally i wouldn’t mind running another service for a specific feature. Of course when services could shared it’s better/nicer. But in the service oriented architectures, it would be fine to have just a seperated service for this.
I see in the source code they lock all the files exclusively, not sure if this is needed. But if so this would rule out memcached, redis does support locking.
ActionCable looks nice, but i didn’t directly see how one rails service could push an message to another. Which i believe is the case here, where the railsserver and scheduler, push message’s to the websocket service, which then pushes them to the client.
Yeah, I guess an ActionCable-based implementation would rather replace the current websocket server completely and use the one provided by ActionCable. That would probably be a bigger refactoring.
My thought as well. However looking at the session.rb implementation, it seems it’s just polling the directory on an interval, so no triggers in an ionotify event. So there is not really a pub/sub between the containers, i guess they just write out a file when the want to send something to the websocket. The logic seems to be just iterate over the files in the directory, parse them, push the to the websocket, and remove the file. In theory this could also live in a database, where each “row” in the table is just read, and removed once complete/message send.
cool! I would expect the zammad maintainers to have it configurable, to either use filesystem or redis…but that’s just a guess.
Ideally instead of polling, it would be event based, for the ultimate interactive experience. But i don’t know which message’s are exactly all handled this way, so maybe it’s overkill too.
Yes, event-based, that’s why I am going to try and use Redis’ BLPOP function, which blocks until there is a new element available (even for multiple lists in parallel).
Sounds good, i think it’s a welcome contribution. One more thought tho, i think it should fallback to the filesystem when redis is not available for what ever reason until you’re able to reconnect. However i’m not sure what would happen in case message’s are missed. Maybe it’s not an issue at all.