Infos:
- Used Zammad version: 3.5.0-8 and 3.6.0-1
- Used Zammad installation source: Docker
- Operating system: CentOS 7
- Elasticsearch: 7.9.3, 2 ingest / data nodes on different local server
Not a bug report, otherwise I’d open a Github issue.
Since recently, we’ve been having issues on one of our two Zammad installations with constant high numbers of background jobs. Most of these seem to be SearchIndexJob (80-90%) which results in new info being indexed with very high delays. But worse, but they also seem to be delaying all kinds of other jobs.
This isn’t the first time we’ve had issues with the indexing, but usually it can be tied to something that actually caused a lot of changes - in that case, you can just wait it out, even if it’s slow. Once before, in a version before 3 I think, we’ve had a similar issue that could be solved by simply deleting all indexing jobs and reindexing from scratch.
Unfortunately, neither waiting nor deleting the jobs seems to help. As for waiting, this is the current behavior:
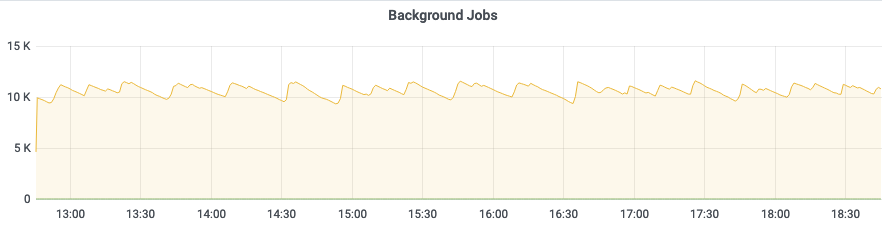
It’s been this high for about two days, for about a week before that it was sometimes under the 8000 threshold of the monitoring controller. So it seems to be going up which is not good - probably means that there are a lot of things that accumulate and don’t get processed at all. Unfortunately, we only noticed it once it showed up in the health check and started causing issues for the users. (Feature request: Always have the number of BG jobs in there and only change the healthy status when they’re over a threshold. That way, we could generate warnings in advance.)
As for deleting the jobs, as soon as I try that, they rapidly start to go up again up to the previous mark. That makes reindexing very hard as Zammad immediately recreates deleted indexes in ES, but only part of them, which is likely a case the reindexing function is not prepared to deal with. I was able to go through reindexing after stopping the scheduler, then deleting the jobs, then reindexing, then starting the scheduler again, but the end result was the above.
Looking at the logs, there’s nothing suspicious - I just see constant reindexing happening but not why. There are a few random errors like unparseable things or timeouts when indexing some attachments but that shouldn’t stop the whole process. ES doesn’t seem to have any error messages or issues - Zammad should be a small part of our data in there and everything else is working as before.
It’s noteworthy that this started about a week after we introduced a new customer sync from our CRM which directly syncs users and companies via the API. We have some 8k users and 3k companies in there, with a significant portion of them having daily changes. (We sync revenue etc.) However, deactivating that sync doesn’t seem to have any effect so it’s not the direct cause. There were also no deletions except a number of empty organizations that were created in error due to an issue with the sync. (Few hundreds, not ten thousand.) We also use the same process on our second Zammad and that department doesn’t have any problems.
Has someone seen this before and can give any advice what to do? I’m afraid that in two weeks, the system might be unusable.
I’ve been through all the threads related to any involved keywords so it’d be new information, but here’s to hoping. Thanks!