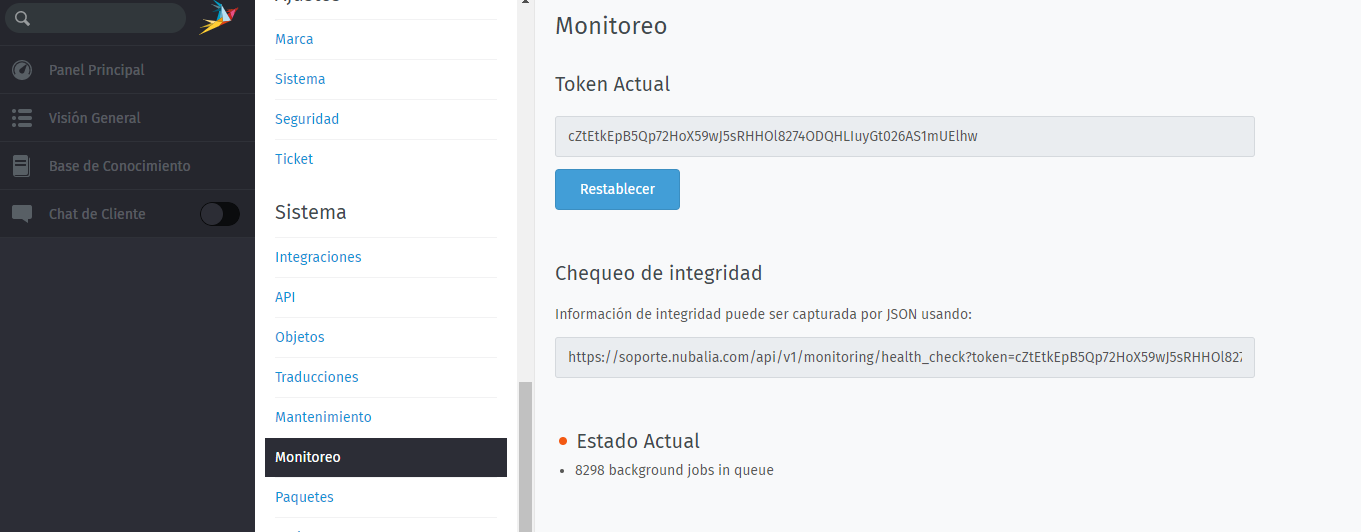
Used Zammad installation source: (source, package, …)
Operating system: Centos
Browser + version: Google Chrome 77.0.3865.90
Hi community,
We are currently using Zammad 3.1.X on a Centos server on Google Cloud Platform and we use all agents and administrators the Chrome browser.
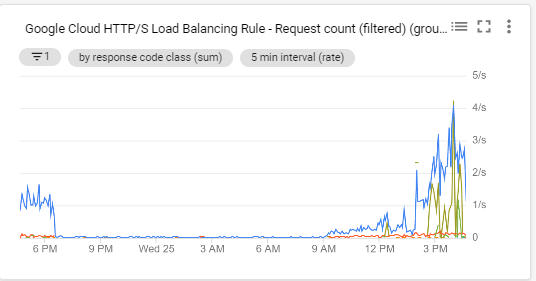
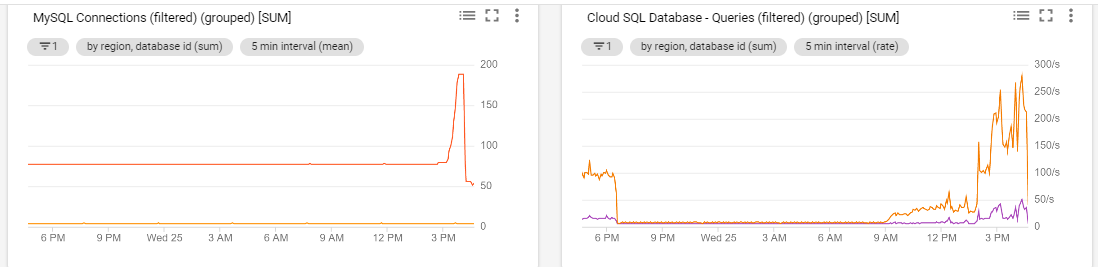
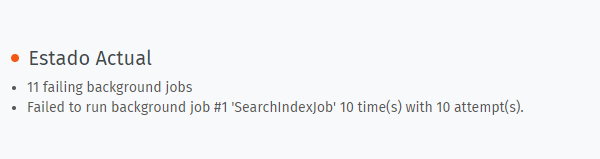
We are happening the case that when the afternoon arrives and more agents enter the platform we start to have the jobs in queue (attached capture), also the requests to our BBDD is triggered (attached capture)
This causes delays in the delivery and reception of emails, in the updating of tickets, etc…
Until now what we do to solve this until the next day that happens again is to restart zammad in the instance where it is and then langar the command to run the pending queue (sudo su zammad -c “zammad run rails r ‘Channel::EmailParser.process_unprocessable_mails’”.
) which is slowly decreasing.
Did the same thing happen to you? Do you know how we can solve it?
Sorry but I have the feeling that you’re mixing up things terribly.
First of all, you’re proberbly having performance issues that may have several reasons.
Please also update the installation type in your first article, because this is a mandatory piece of information! From your screenshot I suspect you’re using MySQL as database, please also add this to your first article (this information seemed to be removed by you from the template)
For us to understand things better, please provide the following information:
Number of cores (and if possible to find out the base speed of each core)
The assigned memory
storage type (proberbly SSD)
Now to the fun part, within a zammad run rails c or rails c (depending on your installation type), run the following commands and provide the output:
· Used Zammad version: 3.1.0-1567466083.396a40e2.stretch (we just updated to 3.1.0-1568967180.6fa1378f.stretch, just in case.)
· Installation source: Debian repository
· Operating system: Debian Stretch
· Cores: 8 (we never see total CPU utilization going over 25%)
· RAM: 30 GB (never above 20%)
· Storage: 20GB SSD (32% used)
· Using mysql2
The issue we’re having is: even with pool size set to 50 in database.yaml, we see MySQL connections reaching 150-200 and Zammad error logs show:
exited with error #<ActiveRecord::ConnectionTimeoutError: could not obtain a connection from the pool within 5.000 seconds (waited 5.336 seconds); all pooled connections were in use
This is the output of the commands provided:
zammad@zammad-1:~$ zammad run rails c
Loading production environment (Rails 5.2.3)
irb(main):001:0> Overview.count
=> 14
irb(main):002:0> User.count
=> 493
irb(main):003:0> User.joins(roles: :permissions).where(roles: { active: true }, permissions: { name: ‘ticket.agent’, active: true }).where.not(id: 1).count
=> 12
irb(main):004:0> Ticket.count
=> 1428
irb(main):005:0> Organization.count
=> 114
irb(main):006:0> exit
Okay, that’s, normally a pool of 50 per process is absolutely fine.
The reason why it’s not can have various reasons, might be the number of request you’re doing to handle within a second or maybe also a slow database.
Any way, you can increase the pool size from let’s say 50 to 75.
This makes a total connection count of up to 300. Please ensure your database server allows that number of connections.
After saving the change, please restart Zammad and wait if the issue appears again.
Please provide logfiles and be a bit more specific on “what problems elasticsearch causes”.
With the above it’s impossible to help you in a good way without fishing in the dark.