Infos:
- Used Zammad version: 6.4
- Used Zammad installation type: zammad -helm (13.0.2)
- Operating system: windows 11
- Browser + version: chrome + Version 144.0.7559.133
Expected behavior:
We have zammad running in k8s, with below resources.
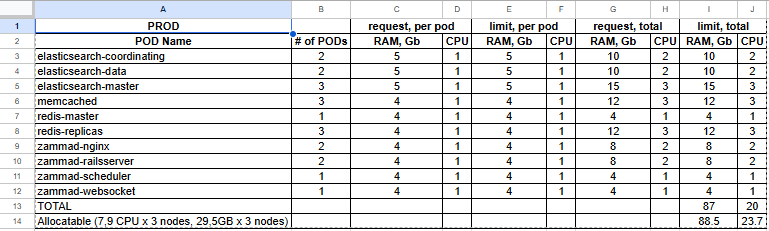
After migrating from other system around 3.3Million tickets, we are rebuilding using 12 cores as below.
nohup bundle exec rake zammad:searchindex:rebuild[12] > /tmp/rebuild_12workers.log 2>&1 &
and we see
zammad@zammad-railsserver-7866bb8f47-29kgn:~$ curl -s ‘http://elasticsearch-master-hl:9200/_cat/indices?v’ | grep zammad_production_ticket
green open zammad_production_ticket QbZeNj4aR8CTRO71ve6pLg 1 1 3334618 0 8.8gb 4.4gb 4.4gb
green open zammad_production_ticket_state 0pq40qZ1SQCnN0dsTOieig 1 1 13 0 234.3kb 71.9kb 71.9kb
green open zammad_production_ticket_priority SsCwo8eMQWyMzkrfKw6P3Q 1 1 5 2 202.2kb 141.1kb
Actual behavior:
I am already pushing resources here, can anyone suggest any ideas how to make it faster?because i don’t have migration window for 12 hrs.
Note: Elastic search pods memory is already maxing out, even i increased for one more pod elastic master initially had only two.

Steps to reproduce the behavior: NA
I understand Index rebuilding is one time heavy task after my migration.
Could you anyone please help me understand the effect of index building with elastic search resource values?
Any benchmark resource values we should maintain for zammad for faster Index building and normal operational resource value.
Any insights are welcome!
*