Used Zammad version: zammad-4.1.0-1630076259.40e648b8.centos7.x86_64
Used Zammad installation type: package
Operating system: Centos 7
Browser + version: any
Expected behavior:
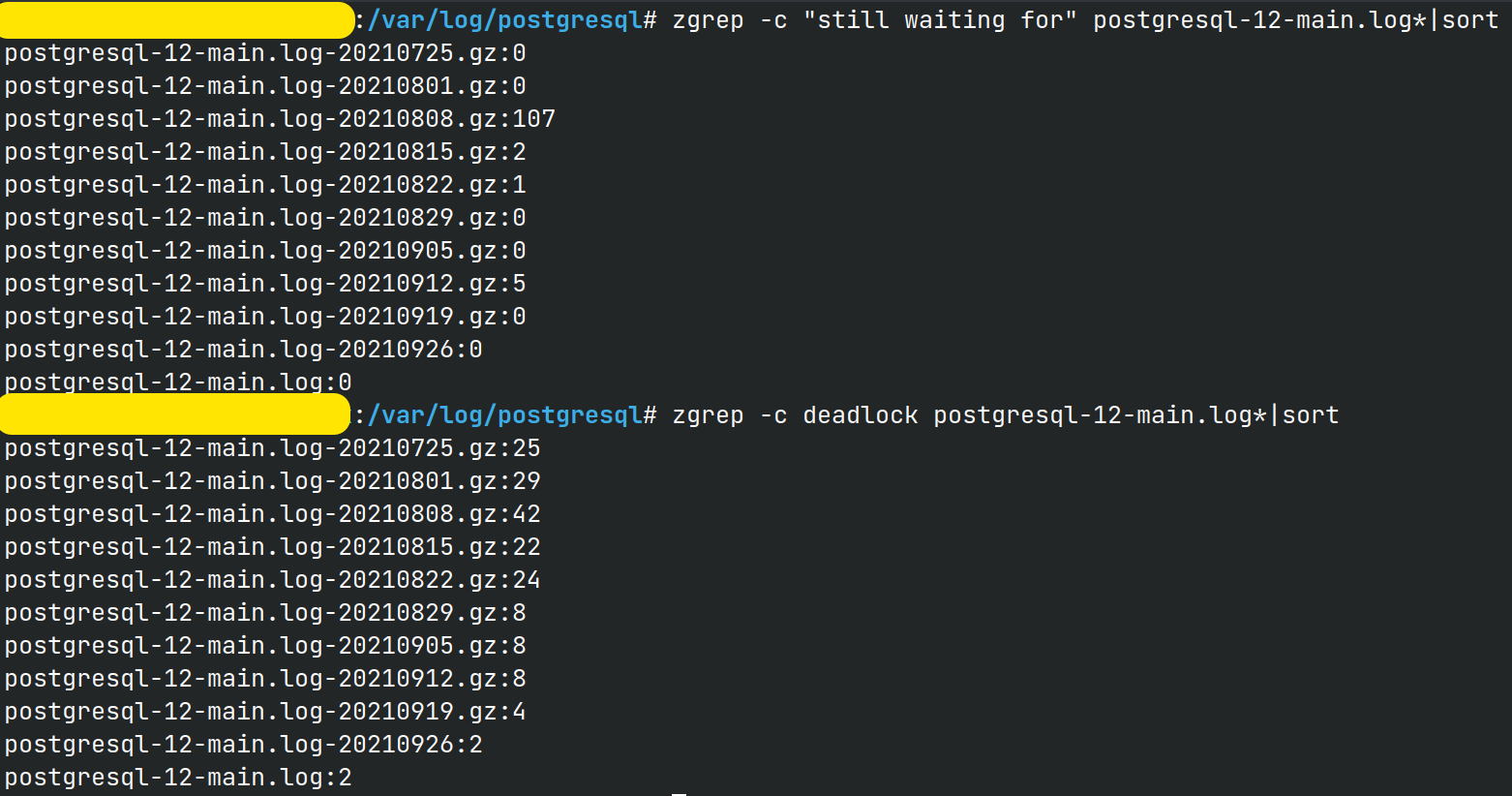
Don’t find deadlocks at the database’s log
Actual behavior:
Very often deadlocks.
2021-09-27 09:41:15 -03 [8614]: [1-1] db=zammad,user=zammad,app=puma: cluster worker 3: 30954 [zammad],client=zammad-web ERROR: se ha detectado un deadlock
2021-09-27 09:41:15 -03 [8614]: [2-1] db=zammad,user=zammad,app=puma: cluster worker 3: 30954 [zammad],client=zammad-web DETALLE: El proceso 8614 espera ShareLock en transacción 5566331; bloqueado por proceso 8607.
El proceso 8607 espera ShareLock en transacción 5566330; bloqueado por proceso 8614.
Proceso 8614: SELECT "taskbars".* FROM "taskbars" WHERE "taskbars"."id" = $1 LIMIT $2 FOR UPDATE
Proceso 8607: SELECT "taskbars".* FROM "taskbars" WHERE "taskbars"."id" = $1 LIMIT $2 FOR UPDATE
2021-09-27 09:41:15 -03 [8614]: [3-1] db=zammad,user=zammad,app=puma: cluster worker 3: 30954 [zammad],client=zammad-web HINT: Vea el registro del servidor para obtener detalles de las consultas.
2021-09-27 09:41:15 -03 [8614]: [4-1] db=zammad,user=zammad,app=puma: cluster worker 3: 30954 [zammad],client=zammad-web CONTEXTO: mientras se bloqueaba la tupla (57,5) de la relación «taskbars»
2021-09-27 09:41:15 -03 [8614]: [5-1] db=zammad,user=zammad,app=puma: cluster worker 3: 30954 [zammad],client=zammad-web SENTENCIA: SELECT "taskbars".* FROM "taskbars" WHERE "taskbars"."id" = $1 LIMIT $2 FOR UPDATE
What kind of a userbase and hardware specs are you running? Did you tune the database or is this a vanilla install (besides the max_connections)?
Our installbase is quite large, with a very busy helpdesk: lots of active agents and incoming e-mails. We were seeing the same sort of lock contending issues and even deadlock situations. We started monitoring and tuning PostgreSQL and now deadlocks and locking issues are significantly less and mostly gone.
Giving advice on tuning parameters is dangerous, as your situation might be completely different compared to ours. We started by logging very slow queries and all lock_waits, which revealed quite a lot of slow queries due to improper database tuning (the next-next-next-finish install). We carefully tuned the database over the course of a few weeks, seeing performance increases and less locking issues appear. We still experience some deadlocks now, but the performance is acceptable at this point. I might be able to give a few hints if I knew more about your config specifics.
Without details on the install/userbase I cannot really judge on performance issues. We are running a fairly large install on a single virtualized node. It has SSD-backed storage, which is probably the reason we haven’t run into major disk I/O-related issues sooner and didn’t feel the need to tune the install. We started getting user complaints about sluggish performance in the Web UI after we increased the number of agents working simultaneously and after an increase in daily received/handled tickets (e-mails).
We will probably look into partitioned tables at some point, as this will be an improvement for trawling trough the amount of tickets and articles we have. We also might be considering switching the attachment-storage to disk instead of in the database. However, you should probably focus on monitoring the basics first: CPU/RAM usage, disk and network latency and not start by immediately deep-diving into index or table optimization.
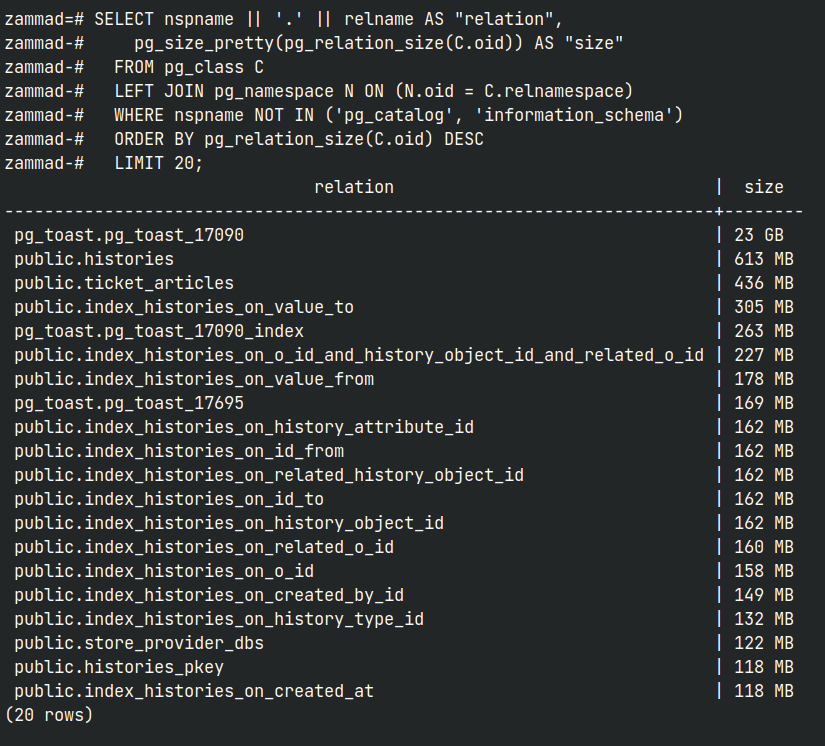
The entire Zammad database is about 29GB in total. Here’s a brief overview on the virtual hardware and load averages. This is just before lunchtime on a typical day. We do have a bit of swap space being used, but swap isn’t thrashing at this point. We might look into that if we start getting complaints about performance.
That’s hella beefy performance settings against the average load you have.
Looks a bit over the top. :x
Deadlocks can happen once or twice in a while. Especially taskbars can be an issue.
What might help is to update Zammad, clear its cache and try to reduce your taskbars.
If you haven’t already, consider using the filesystem as attachment storage to reduce your database servers load on serving binaries.
Dangerzone
Below command destroys ALL existing taskbars - this means DATALOSS if they’re drafts!
However, it allows a clean start with agents not having to cross out single tabs.
Yes, it may seem so. Here is a graph on load averages over the last three months. There are times when we really need(ed) the performance during peak usage. This was usually after an incident, press-conference or some sort of media attention causing lots of new (e-mail) tickets. At those times, delayed jobs were sometimes increasing rapidly, causing lagging in sending/receiving of new tickets and article updates as well as the UI feeling slow while refreshing overviews etc.
Here’s a graph on memory and swap usage over the last three months. We may need to tune PostgreSQL a bit better and look into ElasticSearch performance tuning as well, or do some preventative maintenance and cleanup old tickets and articles. The database wasn’t particularly well-tuned a couple of months ago.
We have seen taskbar queries in PostgreSQL taking a bit of time to complete, sometimes up to a second or two. This is probably due to the fact we have a lot of agents online. About 35 total sessions today, with about 18 concurrent/simultaneous sessions of agents working on tickets. We have done some more tuning on PostgreSQL work_mem, some queries already seem faster at this point.
Indeed, we are looking into moving attachment storage to the filesystem instead of the database, but we are also looking into the possibilities of deleting older tickets from the database.
We are definitely going to update Zammad soon, v5 looks very promising.