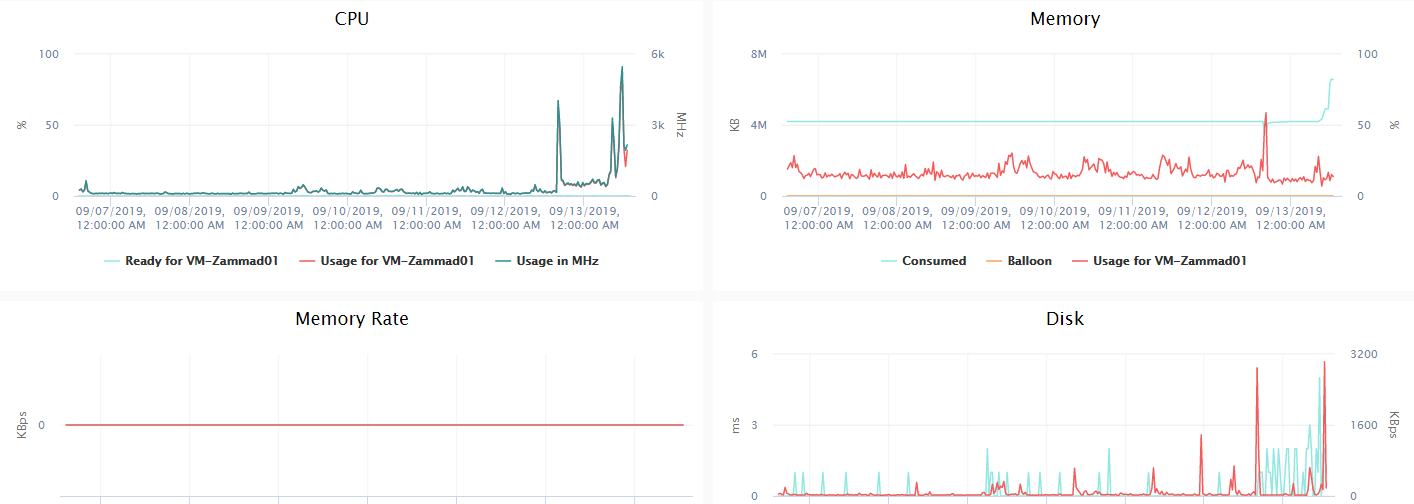
Everything is noticeably slow. We had no changes in our Server Environment or in our VM the one and only diffrent ist that we restored Zammad from a Snapshot yesterday at 4:30 pm.
Noticeable are the Ruby processes for elasticsearch which are shown in the screenshots:
Well this can have various reasons, I’m afraid with the supplied information we can’t help.
What I can see from your graphs that, beside the enormous peak usuage of CPU, it’s close to look like your I/O rised as well.
So what do we need?:
Please provide the virtualization plattform (if any)
provide the hosts CPU type
provide the number of cores assigned to the VM (if it doesn’t give 100% of the hosts CPU, please note that as well)
provide the size of memory assigned to the vm
what’s the storage type? (ssd|hdd|sas|…)
Did you really just restore a snapshot?
How did you restore the snapshot? (e.g.: Did the machine run during the time the snapshot was taken? Did you apply the snapshot during machine runtime? did you restart services afterwards? …)
Also, ensure that your elasticsearch is up and running and check the Delayed-Jobs ( zammad run rails r ' p Delayed::Job.count') and provide the number the command returns (please ).
Did you change the number of concurrent agents working on the system?
How many concurrent agents do you have? Have many overviews? ( Overview.count)
sorry for the late awnser I was since today out of Office.
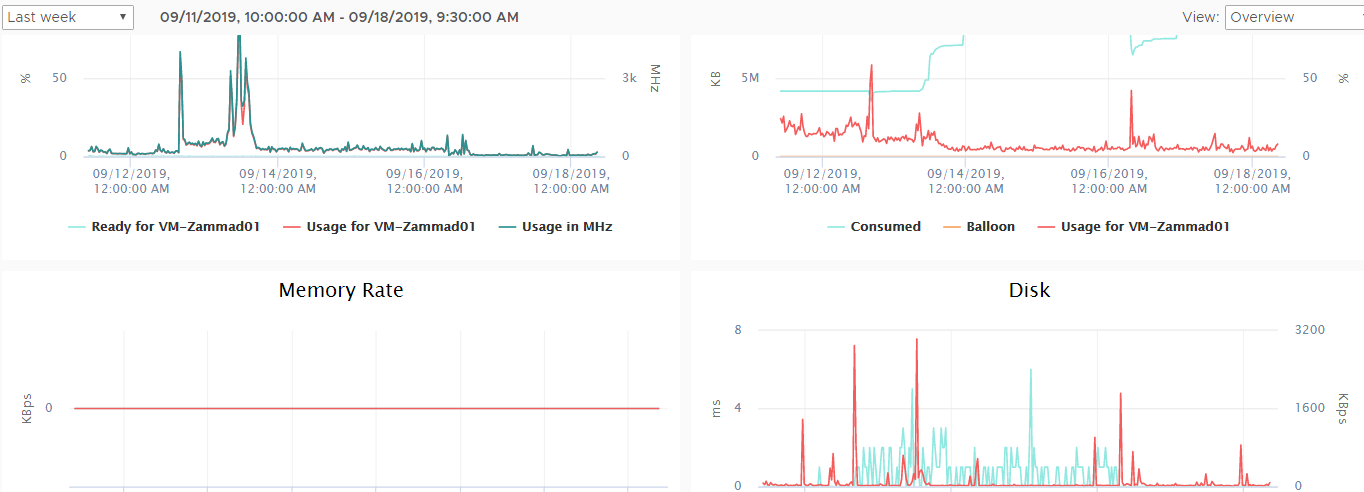
Fortunately the problem was possibly fixed by one of our systech admin. He moved the VM from one esx Server to another, he is on the same harddisk only the “Host” changed.
Don’t know if the problem is fixed cause of the move to another esx host or he had delayed jobs which he processed over the weekend.
Nevertheless I will ask you’r Questions and hope I can help other Users.
Please provide the virtualization plattform (if any)
VMware ESXi, 6.7.0, 10302608
provide the hosts CPU type
Intel(R) Xeon(R) CPU E5-2667 v3 @ 3.20GHz
provide the number of cores assigned to the VM (if it doesn’t give 100% of the hosts CPU, please note that as well)
2 Cores
provide the size of memory assigned to the vm
8 GB
what’s the storage type? (ssd|hdd|sas|…)
SSD
Following steps was made for the Restore:
shutdown vm.
take Snapshot
start vm.
start update with apt-get update and apt-get upgrade
Notice that Update failed and the Web Gui show: 502 Bad gateway.
shut down vm.
Restore from Snapshot via vCenter.
Machine and webserver are alife.
Next day the performance is slow.
The number with the command ( zammad run rails r ' p Delayed::Job.count' ) shows actually “0”.
The strange thing is that the number of agents (5) are the same over the time. Nothing spectacular changed only a few more tickets. There are 11 Overviews.
That’s odd. Maybe this was some kind of temporary situation which can happen, if you have e.g. a high volume of tickets being answered and created by mail. Might be a combination with search indexing.
I suggest to wait until this happens again, the above command for the Delayed-Jobs might indicate time issues on the cpu (so wwe have not enough steam to do all stuff we’d need to do within a timespan).
Note. This does not mean that your hardware is bad, it’s more likely us at the moment. :-x
For ESXi, there’s an option to prioritize CPU time for a VM. I don’t recall it’s exact name, but we had users where it helped to enable this. Kinda the same for KVM, as they seem to try something like fair queueing which might get in your way if you need 100% of a core at that second.