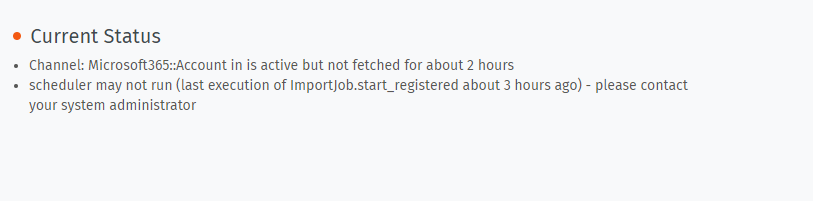
okey, I have solved these issues by rebooting server, increasing CPU, clearing cache in zammad, increasing parameters in conf file of postgres and rebuilding the indexes in elasticsearch
clear cache files:
$ systemctl stop zammad
$ zammad run rails r ‘Rails.cache.clear’
to increase params in conf file of postgres
Raise maximum allowed number of connections
$ sed -i “/max_connections/c\max_connections = 2000”
Caching improvements
$ sed -i “/shared_buffers/c\shared_buffers = 2GB”
$ sed -i “/temp_buffers/c\temp_buffers = 256MB”
$ sed -i “/work_mem/c\work_mem = 10MB”
$ sed -i “/max_stack_depth/c\max_stack_depth = 5MB”
rebuild the indexes in elasticsearch
first check if ingest-attachment is instaled
$ /usr/share/elasticsearch/bin/elasticsearch-plugin list